CloudNet@팀에서 진행하는 AWS EKS Workshop 실습 스터디 참가글입니다.
AWS EKS Workshop을 기반으로, AWS EKS 배포 및 실습하고, 내용을 공유합니다.

1. Amazon EKS 개요
1.1. Amazon EKS 소개
Amazon Elastic Kubernetes Service(Amazon EKS)는 자체 Kubernetes 컨트롤 플레인 또는 노드를 설치, 운영 및 유지 관리할 필요 없이 AWS의 Kubernetes 실행에 사용할 수 있는 관리형 서비스입니다. Kubernetes는 컨테이너화된 애플리케이션의 배포, 확장, 관리를 자동화하기 위한 오픈 소스 시스템입니다.
Amazon EKS 사용 설명서, What is EKS?
Amazon EKS(이하 EKS)는 AWS에서 제공하는 관리형 Kubernetes 서비스이다. 쿠버네티스에 대한 기초 설명은 다른 블로그/공식문서에게 넘긴다.
학습/개발이 아닌 프로덕션 수준의 k8s 클러스터를 구성하는 방법은 크게 2가지 방식이 있다. (k8s doc,Production environment)
- kubeadm, kubespray, kops와 같은 배포 도구를 사용한 구성
- 여러 클라우드회사의 완성형(turnkey) 솔루션 사용하기
운영 환경의 클러스터를 구축하기 위해서는, 가용성/확장성/보안 및 권한 제어와 같이 다양한 제반사항을 고려하여야한다. CSP들의 관리형 서비스를 사용하면, 해당 고려사항을 CSP측에서 해결해주기 때문에 운영 부담이 경감된다.
앞서 언급된 가용성(Availability)/확장성(Scale)/보안 및 권한 제어(Security and access management)등의 고려사항에 대해, EKS는:
- Amazon EKS 사용 설명서, What is EKS?
- 여러 AWS 가용 영역에 걸쳐 Kubernetes 컨트롤 플레인을 실행하고 크기를 조정하여 높은 가용성을 보장합니다.
- 컨트롤 플레인은 하중에 따라 제어 영역 인스턴스의 크기를 자동으로 조정하고, 비정상 제어 영역 인스턴스를 감지하고 교체하며, 자동화된 버전 업데이트 및 패치를 제공합니다.
- 또한 여러 AWS 서비스와 통합되어 다음 기능을 포함한 애플리케이션에 대한 확장성과 보안을 제공합니다.
- 컨테이너 이미지에 대한 Amazon ECR
- 로드 분산을 위한 Elastic 로드 밸런싱
- 인증용 IAM
- 격리를 위한 Amazon VPC
- 오픈 소스 Kubernetes 소프트웨어의 최신 버전을 실행하므로 Kubernetes 커뮤니티에서 모든 기존 플러그 인과 도구를 사용할 수 있습니다. Amazon EKS에서 실행되는 애플리케이션은 온프레미스 데이터 센터에서 실행 중이든 퍼블릭 클라우드에서 실행 중이든 상관없이 모든 표준 Kubernetes 환경에서 실행되는 애플리케이션과 완벽하게 호환됩니다. 즉, 필요한 코드를 수정하지 않고 표준 Kubernetes 애플리케이션을 Amazon EKS로 쉽게 마이그레이션할 수 있습니다.
- Amazon EKS 기능(기능별 상세설명)
와 같은 방식으로 해당 문제를 해결한다. 운영 담당자는 해당 클러스터에 올라갈 어플리케이션(워크로드)들과 워커노드만 관리하면 k8s 클러스터 운영을 손쉽게 제어할 수 있다.
생성하는 각 Amazon EKS 클러스터에 대해 시간당 0.10 USD를 지불합니다. 이런 내구성 있는 기능을 1클러스터/1일 당 약 3천원에 제공한다. AWS 짱짱맨. 물론 EKS를 쓴다는것은 단순히 EKS 클러스터만 생성해서 쓴다는 것이 아니다. 추가 서비스/내부트래픽 증가 등과 같은 hidden cost가 있기 때문에 비용 추이에는 항상 주의를 기울여야한다.
1.2. Amazon EKS 아키텍쳐

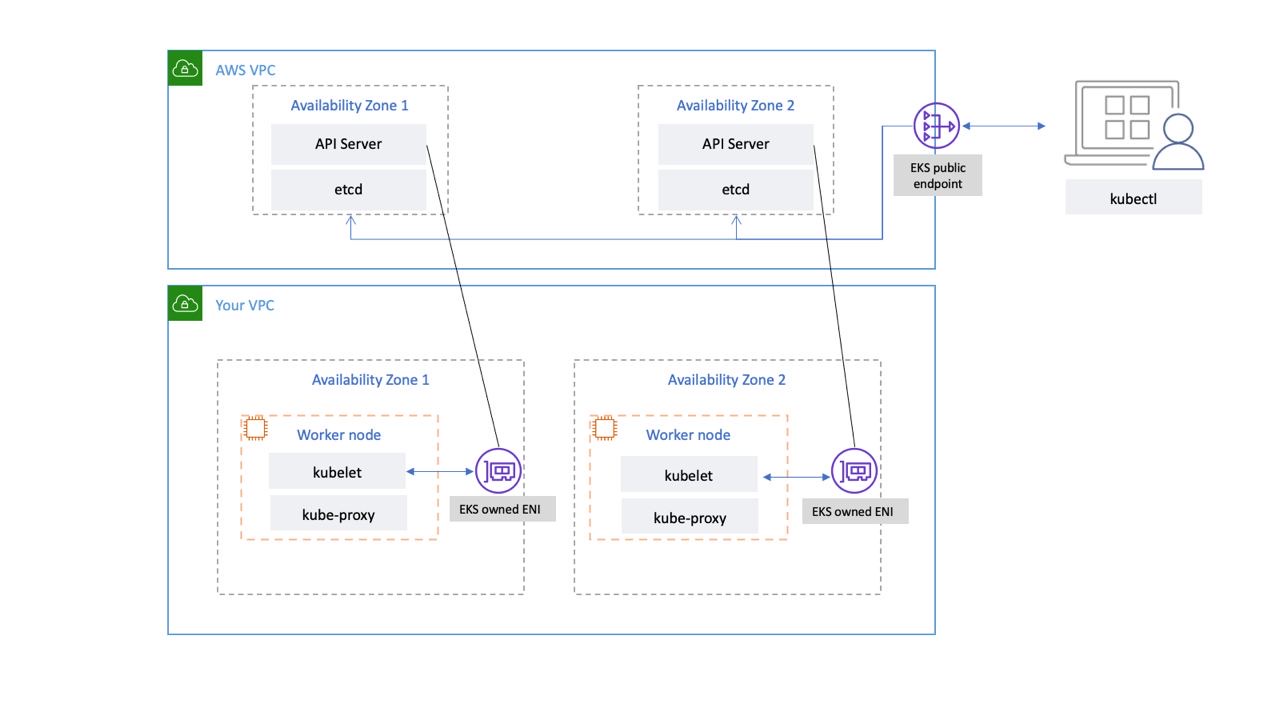
k8s 클러스터는 클러스터를 제어하는 Control Plane(Master Node)과(=머리) / 워크로드가 운영되는 Data Plane(Worker node)로(=몸) 구성된다.
EKS의 경우, 컨트롤 플레인을 AWS 자체적으로 가용성과 내구성있게 구성하여 제공한다.
EKS의 컨트롤 플레인은 사용자의 VPC가 아닌, AWS가 자체적으로 관리하는 AWS managed VPC에 구성된다. 해당 VPC안에 컨트롤 플레인의 구성요소인 API Server, Controller, Scheduler, ETCD 등이 최소 2개의 AZ / 3개의 AZ까지 확장되어 구성된다.
일반적으로 VPC간의 통신은 불가능하다. 따라서 사용자의 VPC에는 AWS VPC와 연결될 수 있도록 별도의 ENI(EKS owned ENI)를 생성하고. 사용자와 워커노드는 해당 ENI를 통해 컨트롤 플레인과 통신이 가능하다. 또한 AWS VPC내에는 NLB가 있어, ENI를 통해 들어온 요청을 각 AZ에 분산된 API서버와 ETCD에 뿌려준다.
Q: kubectl 요청은 HTTPS 요청인데, 왜 ALB가 아니라 NLB를 사용할까?
A: 나름의 생각
1. 컨트롤 플레인의 내부 구성 요소간 통신은 TCP로 이뤄짐
Control plane
| Protocol | Direction | Port Range | Purpose | Used By |
| TCP | Inbound | 6443 | Kubernetes API server | All |
| TCP | Inbound | 2379-2380 | etcd server client API | kube-apiserver, etcd |
| TCP | Inbound | 10250 | Kubelet API | Self, Control plane |
| TCP | Inbound | 10257 | kube-scheduler | Self |
| TCP | Inbound | 10259 | kube-controller-manager | Self |
NLB의 사용 목적은 외부 VPC(ENI)의 요청을 수신하기도 있겠지만, 다중 AZ간 분산되어있는 컨트롤 플레인의 구성요소간의 통신을 연결하는 데에도 사용된다고 생각한다. 그 안에서는 80/443 말고 다른 TCP 통신을 하니까 성능적으로 NLB를 사용하지 않았을까?
2. TCP의 상위 프로토콜을 이해는 못해도, 전달은 할 수 있다.(Direct Server Return, DSR?)
네트워크/클라우드를 공부할 때, 아래의 공식(?)을 달달 외웠었다
- ALB = L7 = HTTP/HTTPS, DNS, SSL 등 = Header/Path를 읽고 트래픽 전달
- NLB = L4 = TCP/UDP = Port에 기반한 트래픽 전달
그래서 L4인 NLB에 L7인 HTTPS가 들어온다면, 내용을 이해하지 못하니까 Drop해버리지 않을까라는 어림짐작을 했었다.
하지만 위의 Q의 의문 해결을 위해 NLB를 공부하다가, 환영님의 AWS Network Load Balancer 쉽게 이해하기 글을 새삼 다시 읽어보았고, Network encapsulation & decapsulation 부분을 다시 찾아 보았다.
NLB에서 HTTPS 패킷을 받는다면, 뭔지 모르겠다 드랍!이 아니라 L2부터 하나씩 decapsulation 하면서 L4까지 올라가서 TCP 포트정보까진 읽은 뒤 해당 포트로 전달하지 않을까? 넘겨준 다음에 처리는 받은 해당 구성요소가 처리하겠지. 라는 상상을 하고 있다.
진짜 패킷 캡쳐해서 까보면 정확하겠지만.. 일단은 상상으로만
(+ 웹서버 EC2앞에 ALB 대신 NLB 붙여놓고 https 접속 되는지 테스트해보기)
1.3. Amazon EKS 배포 방식
EKS를 배포하려면, 보통 아래의 3가지 배포 방식이 존재한다.
- 관리 콘솔(웹)을 사용한 배포
- eksctl(=cloudformation)을 사용한 배포
- terraform eks resource/module 을 사용한 배포
이번 스터디에서는 2. eksctl을 사용한 배포로 진행된다. 테라폼은 테라폼에 대한 러닝커브가 별도로 있기 때문에, eks에 좀더 집중하기 위해서이다.
- eks module을 사용한다면, KMS, Audit Log등 추가 기능이 모두 활성화되어 비용/시간 증가
- eks module을 사용하지 않는다면, 일일히 resource 구성하는데 오랜 시간소요
eksctl은 Amazon의 EC2 기반 관리형 Kubernetes 서비스인 EKS에서, 클러스터를 만들고 관리하기 위한 간단한 CLI 도구입니다. Weaveworks에 의해 만들어졌으며, Go로 작성되었고, CloudFormation을 사용하고, 커뮤니티의 기여를 환영합니다.
eksctl is a simple CLI tool for creating and managing clusters on EKS – Amazon’s managed Kubernetes service for EC2. It is written in Go, uses CloudFormation, was created by Weaveworks and it welcomes contributions from the community.
eksctl – The official CLI for Amazon EKS
eksctl은 EKS 클러스터를 생성하고 관리하는데 사용되는 간단한 CLI 도구이다.
eksctl을 사용해 배포 및 업데이트를 수행하면, cli로 전달받은 파라미터 또는 config 파일을 사용해 AWS CloudFormation Stack을 생성하여 배포 및 업데이트를 수행한다.
Config 파일을 통한 eks 클러스터 관리는 Using config file 문서 또는 하단의 도전과제에서 확인할 수 있다. Config 파일에 대한 schema 또한 eksctl 공식 문서에서 제공한다.
2. EKS 배포 실습

2.1. 기본 인프라 배포
작업용 EC2 생성
# yaml 파일 다운로드
curl -O https://s3.ap-northeast-2.amazonaws.com/cloudformation.cloudneta.net/K8S/myeks-1week.yaml
# 배포
# aws cloudformation deploy --template-file ~/Downloads/myeks-1week.yaml --stack-name mykops --parameter-overrides KeyName=<My SSH Keyname> SgIngressSshCidr=<My Home Public IP Address>/32 --region <리전>
aws cloudformation deploy --template-file myeks-1week.yaml --stack-name myeks --parameter-overrides KeyName=nasirk17 SgIngressSshCidr=43.201.83.181/32 --region ap-northeast-2
# CloudFormation 스택 배포 완료 후 EC2 IP 출력
aws cloudformation describe-stacks --stack-name myeks --query 'Stacks[*].Outputs[*].OutputValue' --output text
# 3.36.77.214
# ec2 에 SSH 접속
예시) ssh -i <My SSH Keyfile> ec2-user@3.35.137.31
ssh -i ~/.ssh/nasirk17.pem ec2-user@$(aws cloudformation describe-stacks --stack-name myeks --query 'Stacks[*].Outputs[0].OutputValue' --output text)작업용 EC2에서, EKS 배포(eksctl)
- IAM User Credential 설정 및 VPC 확인 > 변수 지정
# 필요한 값들 조회/변수 설정
export AWS_ACCESS_KEY_ID=<개인액세스키>
export AWS_SECRET_ACCESS_KEY=<개인시크릿키>
export AWS_DEFAULT_REGION=ap-northeast-2
export AWS_PAGER=""
export CLUSTER_NAME=myeks
export VPCID=$(aws ec2 describe-vpcs --filters "Name=tag:Name,Values=$CLUSTER_NAME-VPC" --query "Vpcs[].VpcId" --output text)
export PubSubnet1=$(aws ec2 describe-subnets --filters Name=tag:Name,Values="$CLUSTER_NAME-PublicSubnet1" --query "Subnets[0].[SubnetId]" --output text)
export PubSubnet2=$(aws ec2 describe-subnets --filters Name=tag:Name,Values="$CLUSTER_NAME-PublicSubnet2" --query "Subnets[0].[SubnetId]" --output text)
echo "AWS_ACCESS_KEY_ID=<개인 액세스 키>" >>~/.bashrc
echo "AWS_SECRET_ACCESS_KEY=<개인시크릿키>" >>~/.bashrc
echo "AWS_DEFAULT_REGION=ap-northeast-2" >>~/.bashrc
echo 'AWS_PAGER=""' >>~/.bashrc
echo "CLUSTER_NAME=myeks" >>~/.bashrc
echo "VPCID=$(aws ec2 describe-vpcs --filters "Name=tag:Name,Values=$CLUSTER_NAME-VPC" --query "Vpcs[].VpcId" --output text)" >>~/.bashrc
echo "PubSubnet1=$(aws ec2 describe-subnets --filters Name=tag:Name,Values="$CLUSTER_NAME-PublicSubnet1" --query "Subnets[0].[SubnetId]" --output text)" >>~/.bashrc
echo "PubSubnet2=$(aws ec2 describe-subnets --filters Name=tag:Name,Values="$CLUSTER_NAME-PublicSubnet2" --query "Subnets[0].[SubnetId]" --output text)" >>~/.bashrc- eksctl 사용 연습: dry-run. 실제 배포는 하지 않음
# eksctl help
eksctl
eksctl create
eksctl create cluster --help
eksctl create nodegroup --help
# 현재 지원 버전 정보 확인
eksctl create cluster -h | grep version
# --version string Kubernetes version (valid options: 1.22, 1.23, 1.24, 1.25, 1.26) (default "1.25")
# eks 클러스터 생성 + 노드그룹없이
eksctl create cluster --name myeks --region=ap-northeast-2 --without-nodegroup --dry-run | yh
# eks 클러스터 생성 + 노드그룹없이 & 사용 가용영역(2a,2c)
eksctl create cluster --name myeks --region=ap-northeast-2 --without-nodegroup --zones=ap-northeast-2a,ap-northeast-2c --dry-run | yh
# eks 클러스터 생성 + 관리형노드그룹생성(이름, 인스턴스 타입, EBS볼륨사이즈) & 사용 가용영역(2a,2c) + VPC 대역 지정
eksctl create cluster --name myeks --region=ap-northeast-2 --nodegroup-name=mynodegroup --node-type=t3.medium --node-volume-size=30 \
--zones=ap-northeast-2a,ap-northeast-2c --vpc-cidr=172.20.0.0/16 --dry-run | yh
# eks 클러스터 생성 + 관리형노드그룹생성(이름, 인스턴스 타입, EBS볼륨사이즈, SSH접속허용) & 사용 가용영역(2a,2c) + VPC 대역 지정
eksctl create cluster --name myeks --region=ap-northeast-2 --nodegroup-name=mynodegroup --node-type=t3.medium --node-volume-size=30 \
--zones=ap-northeast-2a,ap-northeast-2c --vpc-cidr=172.20.0.0/16 --ssh-access --dry-run | yh- EKS 배포
# eks 클러스터 & 관리형노드그룹 배포 전 정보 확인
eksctl create cluster --name $CLUSTER_NAME --region=$AWS_DEFAULT_REGION --nodegroup-name=$CLUSTER_NAME-nodegroup --node-type=t3.medium \
--node-volume-size=30 --vpc-public-subnets "$PubSubnet1,$PubSubnet2" --version 1.24 --ssh-access --external-dns-access --dry-run | yh
# eks 클러스터 & 관리형노드그룹 배포: 총 16분(13분+3분) 소요
eksctl create cluster --name $CLUSTER_NAME --region=$AWS_DEFAULT_REGION --nodegroup-name=$CLUSTER_NAME-nodegroup --node-type=t3.medium \
--node-volume-size=30 --vpc-public-subnets "$PubSubnet1,$PubSubnet2" --version 1.24 --ssh-access --external-dns-access --verbose 43. 관리 편의성 도구 구성
kubectl CLI 플러그인 매니저인 krew와 플러그인들은 사전 구성되어있다.
krew에 대한 설명은 지난 PKOS2 스터디 글 참조
4. 기본 사용
선언형 (멱등성) 알아보기
# 터미널1 (모니터링)
watch -d 'kubectl get pod'
# 터미널2
# Deployment 배포(Pod 3개)
kubectl create deployment my-webs --image=gcr.io/google-samples/kubernetes-bootcamp:v1 --replicas=3
kubectl get pod -w
# 파드 증가 및 감소
kubectl scale deployment my-webs --replicas=6 && kubectl get pod -w
kubectl scale deployment my-webs --replicas=3
kubectl get pod
# 강제로 파드 삭제 : 바라는상태 + 선언형에 대한 대략적인 확인! ⇒ 어떤 일이 벌어지는가?
kubectl delete pod --all && kubectl get pod -w
kubectl get pod
# 실습 완료 후 Deployment 삭제
kubectl delete deploy my-webs[root@myeks-host ~]# k get pod
NAME READY STATUS RESTARTS AGE
my-webs-8dd6b4db-lx2pq 1/1 Running 0 42s
my-webs-8dd6b4db-pms6n 1/1 Running 0 42s
my-webs-8dd6b4db-sqpks 1/1 Running 0 42s
[root@myeks-host ~]# kubectl delete pod --all
pod "my-webs-8dd6b4db-lx2pq" deleted
pod "my-webs-8dd6b4db-pms6n" deleted
pod "my-webs-8dd6b4db-sqpks" deleted
^C[root@myeks-host ~]# k get pod
NAME READY STATUS RESTARTS AGE
my-webs-8dd6b4db-8dwc6 1/1 Running 0 5s
my-webs-8dd6b4db-lnw2q 1/1 Running 0 5s
my-webs-8dd6b4db-lx2pq 1/1 Terminating 0 49s
my-webs-8dd6b4db-n7crg 1/1 Running 0 5s
my-webs-8dd6b4db-pms6n 1/1 Terminating 0 49s
my-webs-8dd6b4db-sqpks 1/1 Terminating 0 49s
> 파드들이 삭제되어도, 다시 새로 만들어져서 복구된다.
이는 deployment로 n(3)개의 replicas를 지정해두었기 때문에, etcd에 선언된 상태(3)와 실제 상태(0)가 일치하지 않으면, deployment 컨트롤러가 다시 선언된 상태 만큼 복구를 시도하기 때문이다. 서비스/파드(mario 게임) 배포 테스트 with CLB
# 터미널1 (모니터링)
watch -d 'kubectl get pod,svc'
# 수퍼마리오 디플로이먼트 배포
curl -s -O https://raw.githubusercontent.com/gasida/PKOS/main/1/mario.yaml
kubectl apply -f mario.yaml
cat mario.yaml | yh
# 배포 확인 : CLB 배포 확인
kubectl get deploy,svc,ep mario
# 마리오 게임 접속 : CLB 주소로 웹 접속
kubectl get svc mario -o jsonpath={.status.loadBalancer.ingress[0].hostname} | awk '{ print "Mario URL = http://"$1 }'
# Mario URL = http://a3b7d5525f1124fe58a6278cff0252ca-594478393.ap-northeast-2.elb.amazonaws.com- 배포 확인 (웹 콘솔)
- EKS > 클러스터 > 리소스 > 서비스 및 네트워킹 > 서비스 > 로드밸런서 URL

- 접속 확인

ECR 퍼블릭 Repository 사용 (us-east-1)
# 퍼블릭 ECR 인증
aws ecr-public get-login-password --region us-east-1 | docker login --username AWS --password-stdin public.ecr.aws
cat /root/.docker/config.json | jq
# 퍼블릭 Repo 기본 정보 확인
aws ecr-public describe-registries --region us-east-1 | jq
# 퍼블릭 Repo 생성
# NICKNAME=<각자자신의닉네임>
NICKNAME=nasir
aws ecr-public create-repository --repository-name $NICKNAME/nginx --region us-east-1
# {
# "repository": {
# "repositoryArn": "arn:aws:ecr-public::596152156334:repository/nasir/nginx",
# "registryId": "596152156334",
# "repositoryName": "nasir/nginx",
# "repositoryUri": "public.ecr.aws/i6e3w3b5/nasir/nginx",
# "createdAt": "2023-04-30T01:07:54.092000+09:00"
# },
# "catalogData": {}
# }
# 생성된 퍼블릭 Repo 확인
aws ecr-public describe-repositories --region us-east-1 | jq
REPOURI=$(aws ecr-public describe-repositories --region us-east-1 | jq -r .repositories[].repositoryUri)
echo $REPOURI
# public.ecr.aws/i6e3w3b5/nasir/nginx
# 이미지 태그
docker pull nginx:alpine
docker images
docker tag nginx:alpine $REPOURI:latest
docker images
# 이미지 업로드
docker push $REPOURI:latest
# 파드 실행 확인
kubectl run mynginx --image $REPOURI
kubectl get pod
# NAME READY STATUS RESTARTS AGE
# mario-687bcfc9cc-q4wgp 1/1 Running 0 16m
# mynginx 1/1 Running 0 2m2s
# 파드 삭제
kubectl delete pod mynginx
# 퍼블릭 이미지 삭제
aws ecr-public batch-delete-image \
--repository-name $NICKNAME/nginx \
--image-ids imageTag=latest \
--region us-east-1
# 퍼블릭 Repo 삭제
aws ecr-public delete-repository --repository-name $NICKNAME/nginx --force --region us-east-1- ECR 확인

관리형 노드에 노드 추가/삭제 Scale
# 옵션 [터미널1] EC2 생성 모니터링
#aws ec2 describe-instances --query "Reservations[*].Instances[*].{PublicIPAdd:PublicIpAddress,PrivateIPAdd:PrivateIpAddress,InstanceName:Tags[?Key=='Name']|[0].Value,Status:State.Name}" --filters Name=instance-state-name,Values=running --output table
while true; do aws ec2 describe-instances --query "Reservations[*].Instances[*].{PublicIPAdd:PublicIpAddress,PrivateIPAdd:PrivateIpAddress,InstanceName:Tags[?Key=='Name']|[0].Value,Status:State.Name}" --filters Name=instance-state-name,Values=running --output text ; echo "------------------------------" ; sleep 1; done
# eks 노드 그룹 정보 확인
eksctl get nodegroup --cluster $CLUSTER_NAME --name $CLUSTER_NAME-nodegroup
# 노드 2개 → 3개 증가
eksctl scale nodegroup --cluster $CLUSTER_NAME --name $CLUSTER_NAME-nodegroup --nodes 3 --nodes-min 3 --nodes-max 6
# 노드 확인
kubectl get nodes -o wide
kubectl get nodes -l eks.amazonaws.com/nodegroup=$CLUSTER_NAME-nodegroup
# 노드 3개 → 2개 감소 : 적용까지 시간이 소요됨
aws eks update-nodegroup-config --cluster-name $CLUSTER_NAME --nodegroup-name $CLUSTER_NAME-nodegroup --scaling-config minSize=2,maxSize=2,desiredSize=25. 도전 과제
5.1. Cluster Endpoint test – Pub/PubPri/Pri
AWS managed VPC에 존재하는 EKS 클러스터의 컨트롤플레인은(api server) Endpoint를 통해 VPC외부와 통신한다. 이때 Endpoint에 대한 액세스 제어를 Public/PublicPrivate/Private 3개의 모드?로 구성할 수 있다.
Public

API 서버 엔드포인트 엑세스가 Public으로 설정되면, API서버로 접근하기 위해서는 외부망을 거쳐서 통신하게 된다.
이를 확인하기 위해, 신규 VPC/클러스터를 생성한뒤, endpoint 경로를 확인해 볼것이다.
Public Access Endpoint test 환경 구성
- 명령어 기반으로 eksctl config yaml 생성
# config file 생성, 과도한 크기의 워커노드가 생성되지않도록 일부 옵션 제한
eksctl create cluster --name yaml --region=ap-northeast-2 --nodegroup-name=ng-default --node-type=t3.medium --node-volume-size=10 --zones=ap-northeast-2a,ap-northeast-2c --vpc-cidr=172.20.0.0/16 --version 1.24 --ssh-access --dry-run >default.yaml
# 워커노드 접속 후 확인을 위한 ssh 설정
29 ssh:
30 allow: true
31 publicKeyPath: ~/.ssh/id_rsa.pub
# 기본값으로 퍼블릭 액세스만 허용
46 vpc:
47 autoAllocateIPv6: false
48 cidr: 172.20.0.0/16
49 clusterEndpoints:
50 privateAccess: false
51 publicAccess: true
# 추후 private 액세스 테스트를 위한 single nat g/w 생성
53 nat:
54 gateway: Single
# config file을 사용한 클러스터 생성
eksctl create cluster -f default.yaml- endpoint 확인을 위한 VPC내 신규 bastion host 생성
- 새로 생성된 eksctl-yaml-cluster/VPC VPC에 웹 콘솔로 생성

- VPC 외부에서, Endpoint에 대해 nslookup

- VPC 내부에서, Endpoint에 대해 nslookup

참고 그림처럼, API Server endpoint에 대해서
둘다 모두 동일한 Public IP를 반환한다는 것을 확인 할 수 있었다.
Public Private

API 서버 엔드포인트 엑세스가 Public,Private으로 설정되면, 외부망과 내부 ENI을 통한 API서버로의 접근이 가능하다.
이를 확인하기 위해, config 파일을 수정하고 업데이트하여, endpoint access 설정을 변경할 것이다
PublicPrivate Access Endpoint test 환경 구성
- default.yaml 파일 수정
# privateAccess false > true
46 vpc:
47 autoAllocateIPv6: false
48 cidr: 172.20.0.0/16
49 clusterEndpoints:
50 privateAccess: true
51 publicAccess: true
# config 파일을 통한 eks cluster 설정 업데이트 > 변경 예정사항 확인
eksctl utils update-cluster-endpoints -f default.yaml
# 2023-04-30 04:16:49 [ℹ] using region ap-northeast-2
# 2023-04-30 04:16:49 [ℹ] current Kubernetes API endpoint access: privateAccess=false, publicAccess=true
# 2023-04-30 04:16:49 [ℹ] (plan) would update Kubernetes API endpoint access for cluster "yaml" in "ap-northeast-2" to: privateAccess=true, publicAccess=true
# 2023-04-30 04:16:49 [!] no changes were applied, run again with '--approve' to apply the changes
# --approve까지 같이 던져줘야 실제 업데이트 수행
eksctl utils update-cluster-endpoints -f default.yaml --approve- VPC 외부에서, Endpoint에 대해 nslookup

- VPC 내부에서, Endpoint에 대해 nslookup

API Server endpoint에 대해서 참고 그림처럼,
VPC 외부에서는 Public IP가 조회되고, VPC 내부에서는 172.20.0.0/16 대역의 내부 IP가 조회되었다.
그럼 해당 Internal IP는 어디에서 왔는가?

User VPC 내부에 생성된 ENI의 Private IP가 Endpoint로 반환되었다는것을 확인할 수 있다.
기본 프라이빗 IP 주소 에서 같은 IP주소, 인스턴스 ID가 비어있다는점에서 워커노드에 부착되어있지않은 별도의 ENI, 소유자(User)의 계정번호와 인스턴스 소유자(AWS)의 계정번호가 다르다는 점을 확인할 수 있다.
Private

API 서버 엔드포인트 엑세스가 Private으로 설정되면, 내부 ENI을 통해야만 API서버로의 접근이 가능하다.
이를 위해선 config에서 cluster에 대한 private 설정과, node에 대한 privatenetworking 설정을 활성하여야한다. 양쪽 모두에 설정을 해야 제대로 생성이 가능하다.
기존 config파일에서 해당 부분을 수정하고 업데이트하면, 부수고 다시만들거 같아 기존 VPC의 정보를 활용한 private cluster를 생성할 것이다.
Private Access Endpoint test 환경 구성
- 공식 문서의 EKS Fully-Private Cluster 문서를 참조한 config 파일 생성
# config 파일 생성
vi private.yaml
# 아래 내역 붙여넣기
apiVersion: eksctl.io/v1alpha5
kind: ClusterConfig
metadata:
name: private-cluster
region: ap-northeast-2
privateCluster:
enabled: true
additionalEndpointServices:
- "autoscaling"
vpc:
subnets:
private:
ap-northeast-2a:
id: subnet-0b4dbfdf5a6edb383
us-west-2c:
id: subnet-03dc33880bac4fbed
nodeGroups:
- name: ng1
instanceType: t3.medium
desiredCapacity: 2
# privateNetworking must be explicitly set for a fully-private cluster
# Rather than defaulting this field to true for a fully-private cluster, we require users to explicitly set it
# to make the behaviour explicit and avoid confusion.
privateNetworking: true
ssh:
allow: true
publicKeyPath: ~/.ssh/id_rsa.pub
# 생성될 서브넷에 관한 데이터를 던져주면, 기존 VPC에 클러스터가 생성된다.
13 vpc:
14 subnets:
15 private:
16 ap-northeast-2a:
17 id: subnet-0b4dbfdf5a6edb383
18 us-west-2c:
19 id: subnet-03dc33880bac4fbed
# privateCluster + VPC endpoint 설정
8 privateCluster:
9 enabled: true
10 additionalEndpointServices:
11 - "autoscaling"
# privateNetwork (Workernode) 설정
28 privateNetworking: true
# 클러스터 생성
eksctl create cluster -f private.yaml- VPC 외부에서, Endpoint에 대해 nslookup

- VPC 내부에서, Endpoint에 대해 nslookup

API Server endpoint에 대해서 참고 그림처럼,
VPC 내/외부에서 동일하게 VPC내의 EKS owned ENI의 IP주소를 반환하였다

Private cluster의 kubectl 실행 불가 문제 해결 (보안그룹)

Fully-Private Cluster를 구성했지만, 너무나 private한 나머지 같은 VPC의 bastion host에서 API 서버로의 접근이 불가능하다. (443:i/o timeout)
이를 해결 + 원인 파악을 위해서는 EKS의 보안그룹의 구조에 대한 이해가 필요하다.
일반적으로 EKS 클러스터를 구성하면, 다음과 같은 3개의 보안그룹이 생성된다.
- 클러스터 보안 그룹 – 통합 보안그룹
- ENI와 워커노드 전체에 부여되서 전체 통신이 항상 가능하도록 한다.
- 클러스터 보안 그룹은 Kubernetes 제어 플레인과 클러스터의 컴퓨팅 리소스 간의 통신을 제어하는 데 사용되는 통합 보안 그룹입니다. 클러스터 보안 그룹은 기본적으로 Amazon EKS에서 관리하는 Kubernetes 제어 플레인과 Amazon EKS API를 통해 생성된 모든 관리형 컴퓨팅 리소스에 적용합니다.
- 추가 클러스터 보안 그룹 (컨트롤플레인 보안그룹)
- ENI에만 부여된다.
- 추가 클러스터 보안 그룹은 계정의 리소스를 컴퓨팅하기 위한 Kubernetes 제어 플레인의 통신을 제어합니다.
- 워커 노드 보안 그룹
- 워커노드에만 부여된다.
- 작업자 노드 보안 그룹은 작업자 노드에서 Kubernetes 제어 플레인으로의 통신을 제어하는 비관리형 작업자 노드에 적용되는 보안 그룹입니다.
위 설명과, 각 보안그룹의 확인은 웹 콘솔 EKS > 클러스터 > 네트워킹 > 보안그룹에서 확인이 가능하다.

그 중, 확인해보아야할 부분은 추가 클러스터 보안 그룹 (컨트롤플레인 보안그룹)이다.
- Public/PublicPrivate 클러스터 구성시

- Private 클러스터 구성시

위의 사진과 같이, Pub/PubPri 구성에서는 외부망을 통해 API 서버로 접근이 가능하기 때문에 별도로 컨트롤플레인 보안그룹을 설정해주지 않아도 통신이 가능하다.
그러나 Private 구성에서는, 내부 ENI를 찍고 들어가야하기 때문에, API 서버에 접근하려면 ENI 보안그룹에 들어오려는 소스를 추가시켜주어야 한다.
- 보안그룹 업데이트


ENI의 보안그룹에, Bastionhost를 원본으로하는 HTTPS 규칙을 추가하면 배스천<>API 서버간 통신이 가능해진다
보안그룹 심화
앞서 EKS 생성방식에는 웹콘솔/eksctl/테라폼의 3가지 방식이 있다는것을 학습했다.
그러나 3가지 방식 각각 보안그룹을 생성/관리하는 스타일이 다르다
해당 내용을 잘 정리한 블로그 글([AWS]EKS Securitygroup(보안그룹) 파헤치기)이 있었으나 그사이 업데이트가 된건지 실제로 각 방식으로 테스트했을때 결과는 다소 다른점이 존재하였다.
- 웹 콘솔로 생성

- eksctl로 생성

- Terraform eks 모듈로 생성

생성방식에 따른 보안그룹의 차이는 결론 그림만 놓고 일단 마무리!
5.2. eksctl Config YAML 파일을 사용해 여러 종류의 노드그룹 테스트
EKS 클러스터의 노드그룹은 한 종류의 노드 그룹으로 고정된 것이 아니라, spec/ami등이 상이한 여러 노드 그룹의 조합으로도 구성할 수 있다. 따라서 사용자는 요구 조건에 맞춰, 다수의 노드그룹이 등록된 클러스터를 조직할 수 있다.
- 노드 그룹의 종류
- 관리형 노드 그룹
- On-demand
- Spot
- 자체 관리형 노드 그룹
- Amazon Linux
- Bottlerocket
- Windows
- Fargate
- 관리형 노드 그룹
5.1.에서 생성한 default cluster에, Spot / Fargate / Bottlerocket등 다양한 종류의 워커노드를 join시켜보는 테스트를 해볼 것이다.
Spot instance
스팟 인스턴스는 온디맨드 가격보다 저렴한 비용으로 제공되는 예비 EC2 용량을 사용하는 인스턴스입니다. 스팟 인스턴스는 큰 할인율로 미사용 EC2 인스턴스를 요청할 수 있게 해주므로 사용자는 Amazon EC2 비용을 대폭 낮출 수 있습니다. 스팟 인스턴스는의 시간당 가격을 스팟 가격이라고 합니다. 각 가용 영역 내 인스턴스 유형별 스팟 가격은 Amazon EC2에서 설정하며, 스팟 인스턴스의 장기적 공급 및 수요에 따라 점진적으로 조정됩니다. 용량을 사용할 수 있을 때마다 스팟 인스턴스가 실행됩니다.
Spot Instances
스팟 인스턴스는 AWS의 유휴 리소스를 저렴하게 할당받아 사용할 수 있는 서비스이다. 일종의 경매처럼 스팟인스턴스의 가격은 지속적으로 변경되며, 설정한 가격 이하의 Spot 인스턴스가 없거나, spot가격이 spot 인스턴스 요청보다 높아져서 상위입찰자가 나타나면 할당받은 인스턴스가 예기치 않게 중단될 수 있어 프로덕션 환경보다는 dev/staging/batch등 방해되어도 괜찮은 워크로드를 다루는 서버에 사용하기가 권장된다.
Spot 인스턴스 노드그룹 추가
- 명령줄로, 기존 클러스터에 Spot 노드그룹 추가하기 (테스트)
# --dry-run 명령어를 사용한 config 파일 생성
eksctl create nodegroup --cluster=yaml --spot --instance-types=t3.small --dry-run >>spot.yaml
# spot 인스턴스임을 표시하는 설정 추가 확인
37 spot: true- 기존 default.yaml에 spot 노드그룹 추가
# default.yaml 편집
vi default.yaml
# managedNodeGroups: 아래에 다음 항목 추가
- name: ng-spot-2
instanceTypes: ["t3.small","t3.medium","t3.large"]
spot: true
volumeIOPS: 3000
volumeSize: 10
volumeThroughput: 125
volumeType: gp3
maxSize: 2
minSize: 2
# 적용 / cluster가 아닌, create nodegroup
eksctl create nodegroup -f default.yaml- Spot 노드 확인 (CLI)
k get node
NAME STATUS ROLES AGE VERSION
ip-172-20-27-96.ap-northeast-2.compute.internal Ready <none> 170m v1.24.11-eks-a59e1f0
ip-172-20-29-73.ap-northeast-2.compute.internal Ready <none> 5m36s v1.24.11-eks-a59e1f0
ip-172-20-49-220.ap-northeast-2.compute.internal Ready <none> 170m v1.24.11-eks-a59e1f0
ip-172-20-55-127.ap-northeast-2.compute.internal Ready <none> 5m44s v1.24.11-eks-a59e1f0
k get node --selector=eks.amazonaws.com/capacityType=SPOT

- Spot 노드 확인 (웹 콘솔)
EC2 > (좌측)인스턴스> 스팟 요청

서울 리전(ap-northeast-2)의 t3.medium의 on-demand 시간당 가격은 0.052USD로, 스팟요청에는 온디멘드 요금까지가 최대치로 설정되어있다. 최대치 이하면 스팟가격으로 사용할 수 있고, 최대치가 되면 아마 중지될 것이다.
현재 사용 금액은 어디서 볼 수 있나 찾아보던 중, 상단의 절감액 요약을 클릭하면 절감액이 표시된다

2대의 최소 사용시간(1시간) 기준 온디멘드는 0.1$지만, 지금 생성한 스팟인스턴스는 0.03$임을 확인할 수 있다,
Fargate
AWS Fargate는 Amazon EC2 인스턴스의 서버나 클러스터를 관리할 필요 없이 컨테이너를 실행하기 위해 Amazon ECS에 사용할 수 있는 기술입니다. Fargate를 사용하면 더 이상 컨테이너를 실행하기 위해 가상 머신의 클러스터를 프로비저닝, 구성 또는 조정할 필요가 없습니다. 따라서 서버 유형을 선택하거나, 클러스터를 조정할 시점을 결정하거나, 클러스터 패킹을 최적화할 필요가 없습니다.
AWS Fargate
AWS Fargate는 서버리스 컨테이너 플랫폼 서비스이다. ECS나 EKS와 같은 서비스를 사용할 시, 컨테이너가 가동되는 플랫폼으로 EC2를 사용할 수 있고, Fargate를 사용할 수 있다. Fargate는 Lambda와 같이 AWS의 대표적인 서버리스 서비스 중 하나고, 호스팅 머신의 구성에 대한 조정할 필요없이 필요한만큼 가동되어 사용된다.
EC2 인스턴스는 생성시 클래스/세대/타입을 설정했던것 처럼, Fargate는 별도의 Fargate profile을 정의하고, 필요한 리소스 생성 요청이 오면 그때그때 필요한만큼 서빙된다..라고 알고있다.
Fargate 노드그룹 추가
- 명령줄로, 기존 클러스터에 Fargate 노드그룹 추가하기 (테스트)
# --dry-run 명령어를 통한 config 파일 생성 후 변경점 확인
eksctl create cluster --fargate --dry-run >> fargate.yaml
# EC2 기반 워커노드와 달리, managedNodeGroups이 아닌 fargateProfiles 로 지정한다.
8 fargateProfiles:
9 - name: fp-default
10 selectors:
11 - namespace: default
12 - namespace: kube-system
13 status: ""
# 해당 부분을 default.yaml로 이동
vi default.yaml- 기존 default.yaml에 fargateProfile 추가
# default.yaml 편집
vi default.yaml
# 공식 문서를 참조하여, 다음과 같은 fargateProfiles 추가
fargateProfiles:
- name: fp-default
selectors:
- namespace: default
labels:
env: dev
checks: passed
- namespace: kube-system
status: ""
# 적용 / cluster가 아닌, create fargateprofile
eksctl create fargateprofile -f default.yamll- 생성 확인
# fargate 노드 생성 확인
k get node -o wide
[root@myeks-host ~]# k get node
NAME STATUS ROLES AGE VERSION
fargate-ip-172-20-76-19.ap-northeast-2.compute.internal Ready <none> 3m34s v1.24.12-eks-f4dc2c0
fargate-ip-172-20-98-217.ap-northeast-2.compute.internal Ready <none> 3m27s v1.24.12-eks-f4dc2c0
ip-172-20-27-96.ap-northeast-2.compute.internal Ready <none> 3h29m v1.24.11-eks-a59e1f0
ip-172-20-29-73.ap-northeast-2.compute.internal Ready <none> 44m v1.24.11-eks-a59e1f0
ip-172-20-49-220.ap-northeast-2.compute.internal Ready <none> 3h29m v1.24.11-eks-a59e1f0
ip-172-20-55-127.ap-northeast-2.compute.internal Ready <none> 44m v1.24.11-eks-a59e1f0
# 어떤 pod가 fargate 쓰는지 찾기
k get pod -A -o wide
...
kube-system coredns-69dbcc544-hrf2d 1/1 Running 0 6m46s 172.20.76.19 fargate-ip-172-20-76-19.ap-northeast-2.compute.internal <none> <none>
kube-system coredns-69dbcc544-pc7ch 1/1 Running 0 6m46s 172.20.98.217 fargate-ip-172-20-98-217.ap-northeast-2.compute.internal <none> <none>
# 왜 coredns만 fargate로 되었는지 pod 정보 확인 > Lable에 fargate-profile 설정
k describe pod -n kube-system coredns-69dbcc544-pc7ch
...
Labels: eks.amazonaws.com/component=coredns
eks.amazonaws.com/fargate-profile=fp-default
k8s-app=kube-dns
pod-template-hash=69dbcc544
...
# 해당 설정을 사용하는 샘플 파드 배포하기
kubectl run fg-nginx --image=nginx --labels=eks.amazonaws.com/fargate-profile=fp-default
k get pod -w
EC2 노드와 달리, 하나의 Fargate 노드는 한개의 pod만 실행된다.(Fargate pod 구성)
문서에서는 ‘Fargateprofile에서 지정된 selector에 따라서, 파드 생성 요청 시 fargate에 예약하려고 시도한다(Fargate 프로파일)’라고 설명되어있다. fargateprofile의 selector가 default namespace를 보고있을테니 임의의 nginx pod 30개를 뿌려보았는데 모두 EC2 노드로 갔다. 지금처럼 EC2+fargate 복합구성의 경우 별도의 우선순위가 있는지? 지금으로썬 명시적으로 label을 붙여줘야 fargate node에 pod가 배정이 된다.
# nginx deployment 생성
k create deployment spamginx --image=nginx --replicas=10
k get pod -o wide
# 20
k scale deployment spamginx --replicas=20
k get pod -o wide
# 30
k scale deployment spamginx --replicas=30
k get pod -o wide
# 50
k scale deployment spamginx --replicas=50
k get pod -o wide50개를 뿌려보았더니 node 제한을 넘어서 배치되지않는 파드가 발생하기 시작했다. 그러면 자연스레 fargate node로 갈 줄 알았는데.. fargate도 한번 써보고 공부해봐야할듯 하다

# 신규 파드들이 배치되지 못하고 있는 모습
# EC2> Too many Pods, Fargate > taint (1노드당 1파드, 이미 파드있음)
k describe pod spamginx-6c8f78d85-9kvf7
...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling 2m47s default-scheduler 0/7 nodes are available: 3 node(s) had untolerated taint {eks.amazonaws.com/compute-type: fargate}, 4 Too many pods. preemption: 0/7 nodes are available: 3 Preemption is not helpful for scheduling, 4 No preemption victims found for incoming pod.
...Bottlerocket
Bottlerocket은 Amazon Web Services에서 컨테이너 실행을 위해 특별히 구축된 Linux 기반 오픈 소스 운영 체제입니다. Bottlerocket은 컨테이너를 실행하는 데 필요한 핵심 소프트웨어만 포함하며, 기본 소프트웨어를 항상 보안합니다. Bottlerocket을 통해 고객은 유지 관리 부담을 줄일 수 있고, 노드를 업그레이드하거나 교체할 때 구성 설정을 일관되게 적용하여 워크플로를 자동화할 수 있습니다.
Bottlerocket, 컨테이너 실행을 위해 특별히 구축된 Linux 기반 운영 체제
Docker Image를 Build할때 경량화된 Alpine을 사용하듯이, 컨테이너 환경에 최적화/경량화된 OS로만 알고 있다. 기본적인 SSH/쉘등 많은 부분이 생략되었기때문에 운영상에 불편함은 있지만, ISMS 같은 보안인증시에는 그런점에서 도움이된다는 이야기를 들었다.
Bottlerocket 노드그룹 추가
- 명령줄로, 기존 클러스터에 Bottlerocket 노드그룹 추가하기 (테스트)
# --dry-run 명령어를 통한 config 파일 생성 후 변경점 확인
eksctl create cluster --node-ami-family=Bottlerocket --dry-run >> bottlerocket.yaml
# amiFamily가 AmazonLinux2가 아닌 Bottlerocket이고, 별도 설정값을 입력할 수 있다.
14 managedNodeGroups:
15 - amiFamily: Bottlerocket
16 bottlerocket:
17 settings: {}
# 기존 volume 설정외에 volumeName이 설정되어있음
54 volumeIOPS: 3000
55 volumeName: /dev/xvdb
56 volumeSize: 80
57 volumeThroughput: 125
58 volumeType: gp3
# 해당 부분을 default.yaml로 이동
vi default.yaml- 기존 default.yaml에 Bottlerocket 노드그룹 추가
# default.yaml 편집
vi default.yaml
# 공식 문서를 참조하여, 다음과 같은 bottlerocket 설정 추가
- name: ng-bottlerocket
amiFamily: Bottlerocket
bottlerocket:
settings: {}
ssh:
allow: true
publicKeyPath: ~/.ssh/id_rsa.pub
volumeIOPS: 3000
volumeName: /dev/xvdb
volumeSize: 10
volumeThroughput: 125
volumeType: gp3
# 적용 / cluster가 아닌, create nodegroup
eksctl create nodegroup-f default.yamlBottlerocket 작동 확인
- 워커노드 확인
k get node --selector=alpha.eksctl.io/nodegroup-name=ng-bottlerocket
NAME STATUS ROLES AGE VERSION
ip-172-20-40-244.ap-northeast-2.compute.internal Ready <none> 10m v1.24.10-eks-08ad9cc
ip-172-20-9-98.ap-northeast-2.compute.internal Ready <none> 10m v1.24.10-eks-08ad9cc- 해당 노드에 파드 배치 확인 (node selector)
# bottle 로켓에 os=bottlerocket label 부여
# k label nodes <node1> <node2> os=bottlerocket
k label nodes ip-172-20-40-244.ap-northeast-2.compute.internal ip-172-20-9-98.ap-northeast-2.compute.internal os=bottlerocket
# 해당 label을 보고 배치되는 deployment 생성
k create deployment nginx --image=nginx --replicas=10 --dry-run=client -o yaml >>deploy2.yaml
# deploy2.yaml에 node selector 추가
19 spec:
20 nodeSelector:
21 os: bottlerocket
# deployment 배포
k apply -f deploy.yaml
k get pod- 워커노드에 ssh 접속
- 작업용 EC2의 id_rsa키를 배스천에 옮겨넣어서 접속테스트 수행
- ssh 접속

Bottlerocket에 대해서는 Hyperconnect의 기술블로그에 있는 Shell 없는 Container, Live 환경에서 Debugging해보기!, Bottlerocket in Production Kubernetes Cluster를 통해 어떤 OS인지 느낌을 받았었다.
그리고 그 글 중에서, 아래 파트를 보고 디버깅용 컨테이너를 구동하고, 그곳에서 디버깅한다는 아이디어에 나름 감명을 받았었다.
따라서, 다음과 같은 전략을 사용하여 실행 중인 Pod의 container를 어떠한 조작도 없이 현재 상태 그대로 디버깅할 수 있습니다.
- 먼저 debugging 도구가 잔뜩 설치되어 있는 이미지를 만듭니다.
- 위에서 만든 이미지를 원하는 Pod에 추가하여 root 권한으로 실행합니다.
- 2에서 추가한 새 container는 Pod 내의 다른 container와 몇몇 namespace를 공유하므로 동일 환경에서 디버깅이 가능합니다!
물론 2번째 단계를 실행하는 것은 불가능합니다. Pod 내의 container definition을 포함한 대부분의 spec은 immutable하므로 한 번 생성된 이후에는 수정 할 수 없습니다.
Shell 없는 Container, Live 환경에서 Debugging해보기!
그런데 bottlerocket os들어오니까 나름 그러한 기능을 구현한듯 하다?!
ec2-user로 ssh 로그인하면, Host 파일시스템과 각종 디버깅 툴들이 설치된 admin container로 떨어지게된다. 어드민 컨테이너에서 디버깅 작업을 할 수 있고, 필요하다면 특정 명령어를 통해 호스트시스템의 root로 전환할 수 있다. (sudo sheltie)
별생각없이 들어와봤는데 와 재밌네
마무리
일련의 실습을 통해 하나의 클러스터에서, 단순 EC2기반 워커노드 뿐만 아니라 Spot instance / Fargate / Bottlerocket등 여러 유형의 워커노드들을 join시켜 보았다. 찍먹수준이긴 하지만, 항상 해보고싶었던거라서 일단 이정도에 만족한다.
eksctl config
apiVersion: eksctl.io/v1alpha5
availabilityZones:
- ap-northeast-2a
- ap-northeast-2c
cloudWatch:
clusterLogging: {}
iam:
vpcResourceControllerPolicy: true
withOIDC: false
kind: ClusterConfig
kubernetesNetworkConfig:
ipFamily: IPv4
managedNodeGroups:
- amiFamily: AmazonLinux2
desiredCapacity: 2
instanceSelector: {}
instanceType: t3.medium
labels:
alpha.eksctl.io/cluster-name: yaml
alpha.eksctl.io/nodegroup-name: ng-default
maxSize: 2
minSize: 2
name: ng-default
privateNetworking: false
releaseVersion: ""
securityGroups:
withLocal: null
withShared: null
ssh:
allow: true
publicKeyPath: ~/.ssh/id_rsa.pub
tags:
alpha.eksctl.io/nodegroup-name: ng-default
alpha.eksctl.io/nodegroup-type: managed
volumeIOPS: 3000
volumeSize: 10
volumeThroughput: 125
volumeType: gp3
- name: ng-spot-2
instanceTypes: ["t3.small","t3.medium","t3.large"]
spot: true
volumeIOPS: 3000
volumeSize: 10
volumeThroughput: 125
volumeType: gp3
maxSize: 2
minSize: 2
- name: ng-bottlerocket
amiFamily: Bottlerocket
bottlerocket:
settings: {}
ssh:
allow: true
publicKeyPath: ~/.ssh/id_rsa.pub
volumeIOPS: 3000
volumeName: /dev/xvdb
volumeSize: 10
volumeThroughput: 125
volumeType: gp3
fargateProfiles:
- name: fp-default
selectors:
- namespace: default
labels:
env: dev
checks: passed
- namespace: kube-system
status: ""
metadata:
name: yaml
region: ap-northeast-2
version: "1.24"
privateCluster:
enabled: false
skipEndpointCreation: false
vpc:
autoAllocateIPv6: false
cidr: 172.20.0.0/16
clusterEndpoints:
privateAccess: true
publicAccess: true
manageSharedNodeSecurityGroupRules: true
nat:
gateway: Single
5.3. Pod Scheduling Strategy
쿠버네티스에서 스케줄러는 기본적으로 노드의 자원가용량을 고려해 파드를 배치한다.
그러나 실제로 클러스터를 운영하다보면, 특정 성격을 가진 파드는 특정 노드에 배치하는 필요가 생기게 된다.
가령, 여러팀이 하나의 개발 클러스터를 공유한다면 팀마다 하나정도라도 전용노드 / 여분의 공용노드의 구성이라던지,
컴퓨팅 최적화 인스턴스인 C클래스와, 메모리 최적화 인스턴스인 R클래스로 각각 노드그룹을 구성했을 때, 각 어플리케이션별로 적절한 워커노드를 찾아가는 식의 구성이 그 예시일 것이다.

이러한 파드의 배치 전략을 고민하고 구현하기 위해서 k8s에서는 여러 구현 요소가 존재한다.
- Labels & Selector
- Pod Affinity & Anti-Affinity
- Taints & Tolerations
- Resource limit
- Scheduler Events
5.2의 실습에서 다양한 노드그룹을 구현한것도 이제 이런 파드 배치전략 실습하려고 한건데.. 날이 새버렸다. 다음 기회에..
6. 마무리
- EKS 워크샵 끝까지 잘 씹어먹기
EKS 워크샵은 2번정도 오프라인 교육에 참가해보기도 했었다. 하지만 하루 이틀내에 전체를 다루기엔 너무 방대한 양이기도 하고, (본인을 포함한) 같이 참가한 다른 사람들을 보면 대부분 워크샵 패턴은 비슷했다.
- 처음엔 의욕적으로 설명 듣고, 열심히 읽고 따라함
- 중간부터 설명 안 읽고 커맨드 복붙하고 결과만 확인함
- 2048/마리오/테트리스 ELB 연결되는 순간 자체 종강 > 고득점 내기
- 교육 종료 후, 24시간 동안 권한 유지되니 집에 가서 마저 끝낼 생각함
- 안함
7주동안의 기간인 만큼 하면서 궁금하고 해보고 싶었던 내용들을 다 해볼 생각이다.
- 찍먹의 즐거움
무엇보다 이번 1주차에서는 항상 ‘한번쯤 써봐야지..’ 했던 Spot, Fargate, Bottlerocket을 다른 가이드 없이 문서만 보고 찍먹해본게 만족감이 컸다. 나름 항목마다 그 다음 해볼것들이 떠오르기도 하고. (Spot 인스턴스 중단이 어떻게 일어나는지 모니터링켜놓고 보기 / Fargateprofile은 어떻게 구성하는지, EC2랑은 어떻게 다른지 / Bottlerocket AML과는 다른 OS인 만큼 또 다른 특이점이 어떤게 있는지)

스터디 모임장 가시다입니다.
EKS 기초 및 아키텍처와 노드그룹을 정말 상세히 잘 정리해주셨네요.
남은 6주도 잘 부탁드립니다!