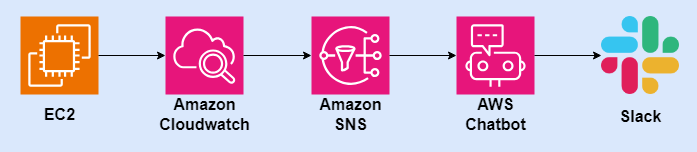
Intro
기존에 사용하던 모니터링 솔루션의 비용절감을 위해, 별도의 툴을 사용하지 않고, 사용하는 플랫폼(AWS)에서 제공하는 서비스만으로 간단하고 저렴하게 모니터링과 알람을 구현하는 방법을 알아보게되었다.
여러 레퍼런스를 살펴보았을때 제일 간편하고 빠르게 구성할 수 있는것은 AWS Cloudwatch + Chatbot의 조합이였다. 본글에서는 해당 서비스를 사용해 간편히 시스템 지표(CPU 사용량>80)에 대한 모니터링 알람을 구성하고, Slack으로 메세지를 받는 과정을 정리해두고자 한다.
SNS 주제 생성
추후 생성할 Cloudwath Alarm과 SNS Chatbot을 연결할 것이다.
원하는 이름으로 생성해두면 된다.
Cloudwatch Alarm 생성하기
별도의 cloudwatch agent를 사용하지 않았을 경우, 기본 cloudwatch가 수집하는 메트릭은 다음 링크와 같다. 기본적으로 5분 간격으로 수집되며, CPU/EC2 상태체크와 같은 지표가 수집된다.
Memory, Disk와 같은 추가 지표는 원하는 대상(EC2)에 별도의 Cloudwatch Agent를 설치하고, 수집 대상/주기 등의 설정이 필요하다. Agent가 추가로 수집 가능한 메트릭은 다음 링크와 같다.
경보 생성을 위한 절차는 다음과 같다.
1. Cloudwatch 콘솔에서 경보 생성 클릭
AWS 웹 콘솔에서 Cloudwatch 콘솔로 접근한 뒤, 우측 상단의 경보 생성을 클릭하여 새로운 생성 페이지로 진입한다.
2. 지표 선택에서 경보 생성을 하고자 하는 지표를 선택한다.
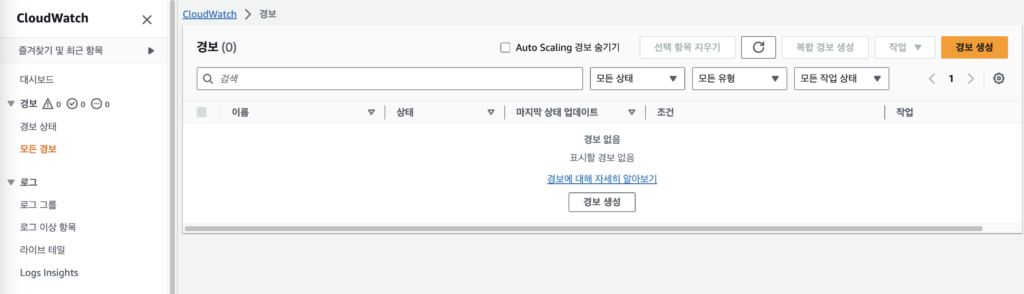
경보 생성의 첫 단계는 지표 및 조건 지정이다. 화면의 지표 선택을 통해 필요한 지표(metric)을 선택한다.
이번 예제에서 설정하고자하는 CPU 사용량(CPUUtilization)은 AWS/EC2 네임스페이스에 속해있다. 처음 AWS 네임스페이스에서 EC2를 선택한뒤 여러 지표 중 해당 지표를 찾거나, 또는 검색창에 MetricName="CPUUtilization"을 검색하여 해당 지표의 모든 인스턴스를 검색할 수 있다.
그러나 모든 인스턴스를 하나의 경보로 등록하는 것은 불가능하다. (계속하려면 단일 지표를 선택합니다.)
CPUUtilization 메트릭은 기본적으로 하나의 인스턴스당 하나의 지표로 생성되고, 각 CW Alarm에는 하나의 지표만 연결이 가능하기 때문이다.
3. 수학표현식을 사용해 다수 Metric 통합하기
동일한 지표이름을 갖는 여러 인스턴스 그룹에 대한 경보를 만들기 위한 AWS에서의 공식적인 방법은 각 개별 인스턴스마다 알람을 만들고, 이를 묶은 복합 경보를 만드는 것이다.
그러나 일일히 모든 경보에 대해 알람을 생성하고 복합 경보로 연동하는 것은 과정도 반복적이고 개별 인스턴스가 추가삭제될때마다 관리적인 측면에서도 쉽지 않다.
다른 방법으로는, 수학표현식으로 여러 인스턴스를 묶어서 그 값을 CW Alarm의 조건으로 설정할 수 있다.
지금처럼 등록된 인스턴스 중, 한대라도 CPU 사용량이 80%을 넘을것의 경우에는 MAX 조건을 사용할 수 있다. 생성하고자하는 알람의 조건에 따라, 최소사용량이 필요한 경우 MIN 조건을 사용할수도 있고, ALB의 헬스체크를 감지하는 알람을 생성하고자하면 SEARCH 함수를 사용할 수 있다.
찾아보기 옆의 다중 소스 쿼리로 이동 한 후, AWS/EC2 네임스페이스의 CPUUtilization 값의 MAX를 조회하도록 설정한다. 편집기로 입력하는 쿼리문은 다음과 같다.
SELECT MAX(CPUUtilization) FROM SCHEMA("AWS/EC2", InstanceId)
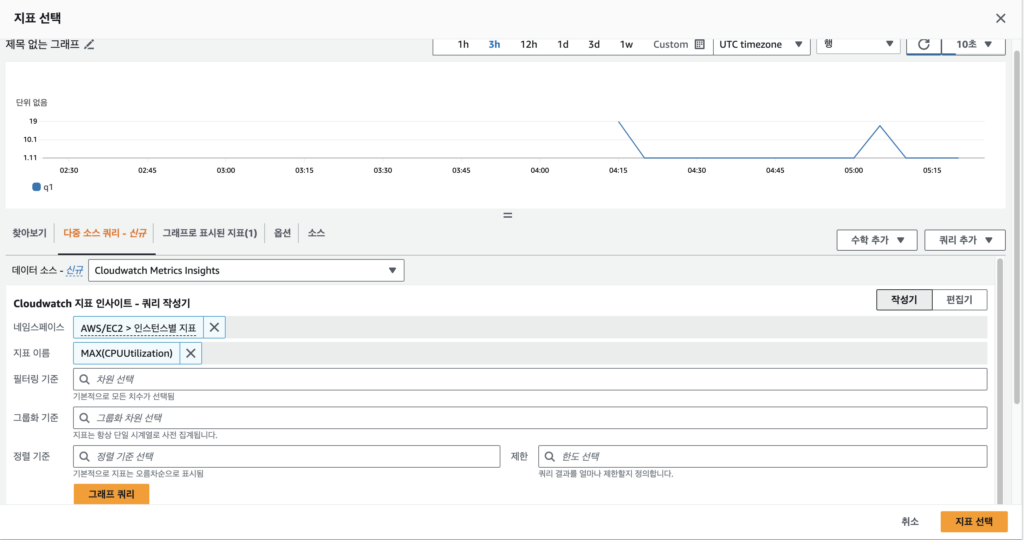
쿼리를 실행하면 지표가 추가되고, 지표 선택을 눌러 추가가 가능하다.
4. 알람 조건 설정하기
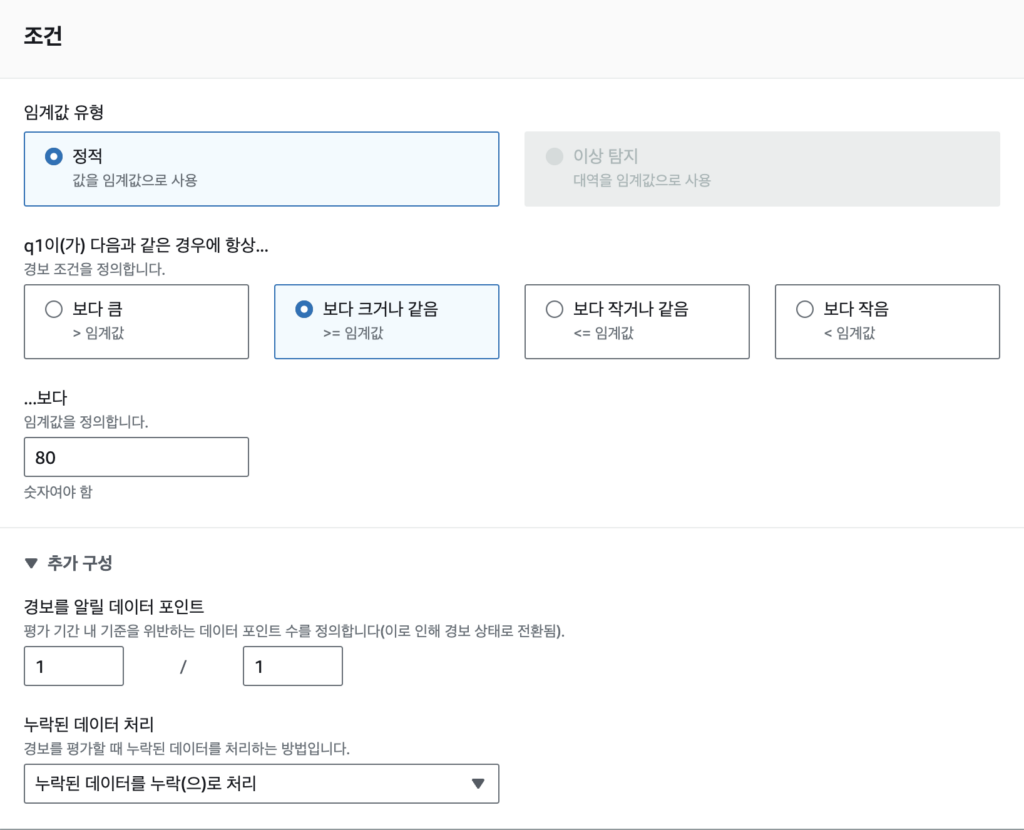
조건 탭에서는 알람 발생 임계값, 데이터포인트, 누락데이터 처리를 설정할 수 있다.
임계값의 경우, 위에서 설정된 지표의 값이 설정된 임계값보다 작거나 클때 알람이 발생된다. 지금의 경우 80이상이나 >= 80을 설정한다.
데이터 포인트의 경우, 알람 발생을 위한 대기기간이다. n/m의 데이터 포인트라면, 총 m번의 평가기간 중 n번 이상 임계값을 넘어야 알람이 발생된다.
기본값인 1/1인 경우, 1회의 평가기간(5분의 기간)동안 1회라도 넘으면 바로 알람이 발생되고, 2/3으로 설정하면 3회의 평가기간(각5분)중 2번 이상 임계값이 넘어야 알람이 발생된다.
누락된 데이터 처리의 경우 메트릭 값이 들어오지 않을경우 알람의 처리방법을 설정한다. 기본값은 별도의 누락상태로 전환하는것이며, 설정에따라 누락되어도 OK, 이전상태 유지, 경보 발생 등으로 전환할 수 있다.
5. 상태 트리거 설정하기
AWS Cloudwatch 알람은 경보(Alert)/정상(OK)/데이터부족(Missing) 3개 중 하나의 상태값을 갖는다.
알람을 받고자 하는 각 상태를 알림에 추가해준다.
6. 이름 및 설명 추가하기
원하는 알람 이름과 설명을 추가하여 생성 과정을 마무리한다.
AWS Chatbot 생성하기
1. AWS Chatbot 클라이언트 구성
AWS 웹 콘솔에서 AWS Chatbot 서비스로 접근한 뒤, slack 채팅 클라이언트를 구성한다.

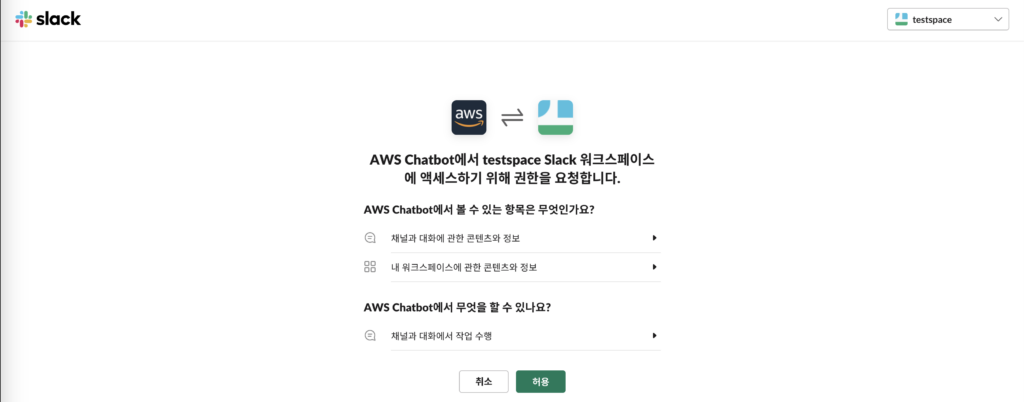
2. 클라이언트 권한 허가
클라이언트 구성 버튼을 클릭하면 다음과 같이 권한 요청(연동)페이지가 뜬다. 우측 상단에서 연동하고자 하는 slack workspace를 선택한 뒤 연동한다.
3. 채널 구성
생성된 workspace에 알람을 받을 채널을 추가할 것이다. 새 채널 구성을 클릭하여 구성 페이지로 이동한다.
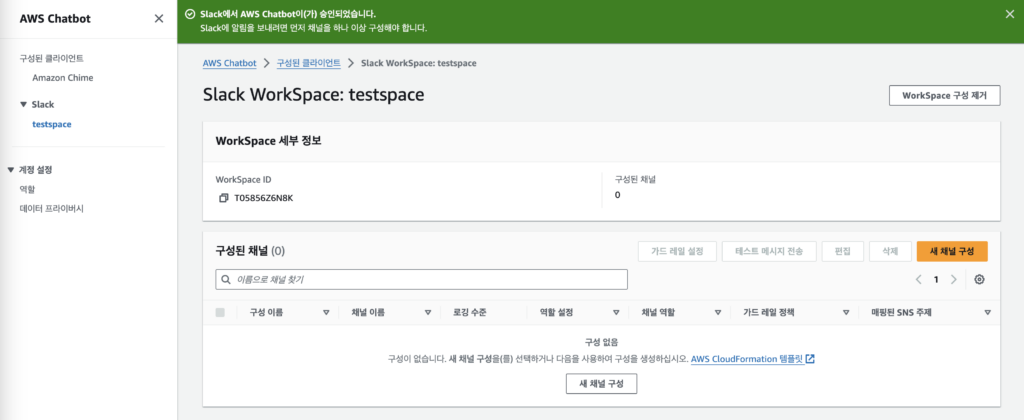
구성 이름에는 원하는 이름을 입력하고, 연동할 채널 이름을 선택한다.
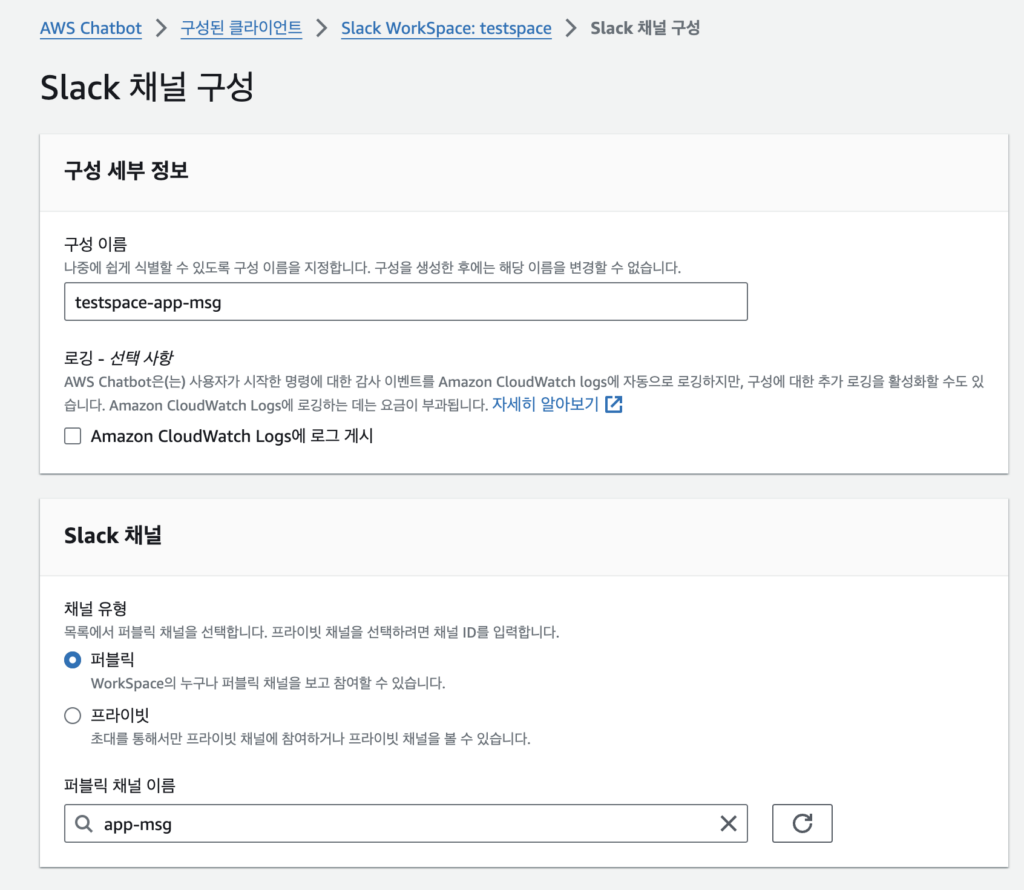
권한부여
채널에 추가될 AWS Chatbot이 수행할 역할을 설정한다.
크게 정책 템플릿과 가드레일 두개의 권한으로 나누어 볼 수 있다. 정책 템플릿은 채널내에서 chatbot이 수행할 수 있는 허용권한 / 가드레일은 수행할 수 없는 금지권한으로 이해할 수 있다.
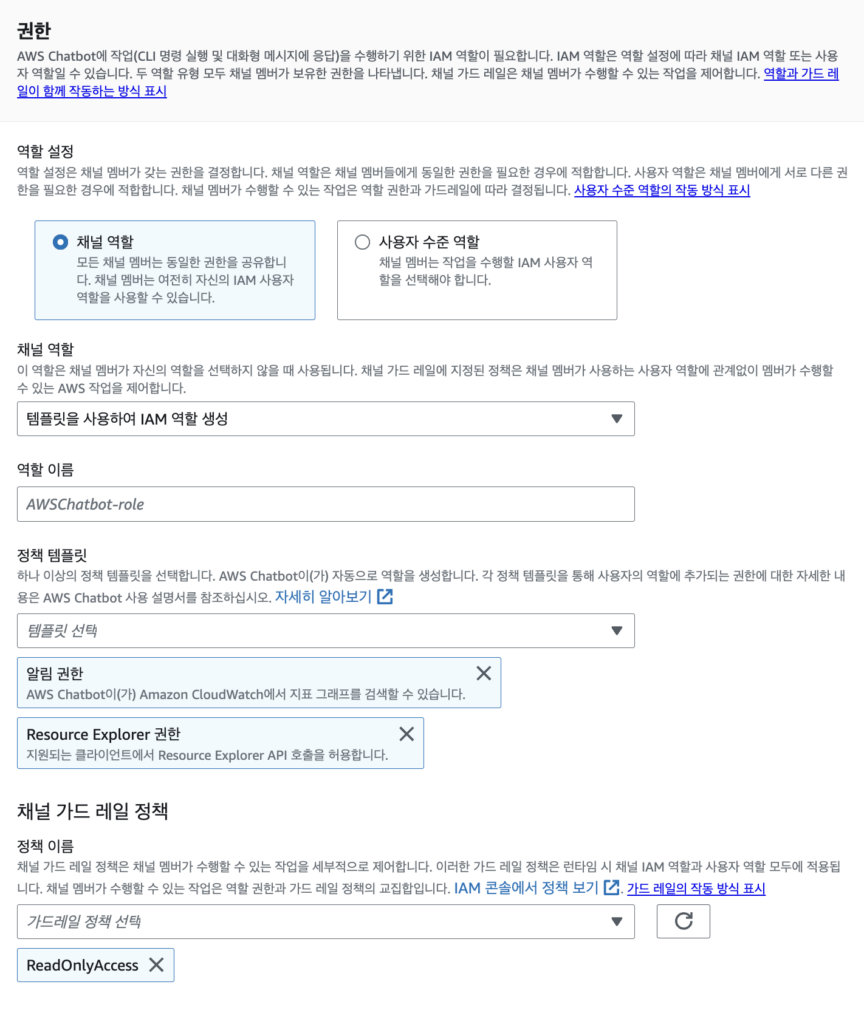
SNS 연결
위의 Cloudwatch Alarm이 연동된 SNS 주제를 추가해준다.
알람 테스트 하기
생성 및 등록된 Cloudwatch Alarm이 잘 작동하고, 알람 메세지가 잘 들어오는지 확인하기 위해 인스턴스 중 하나에 CPU 부하를 줄것이다.
cpu 부하를 주기 위해 stress 라는 도구를 설치할것이고, 설치를 위해 epel package가 필요하다
# amazon-linux-extra를 통한 epel 설치
sudo amazon-linux-extras install epel -y
# stress 설치
sudo yum install stress -y
# 2 cpu를 대상으로, 100분(6000초)간 부하 발생
stress -c 2 -t 6000
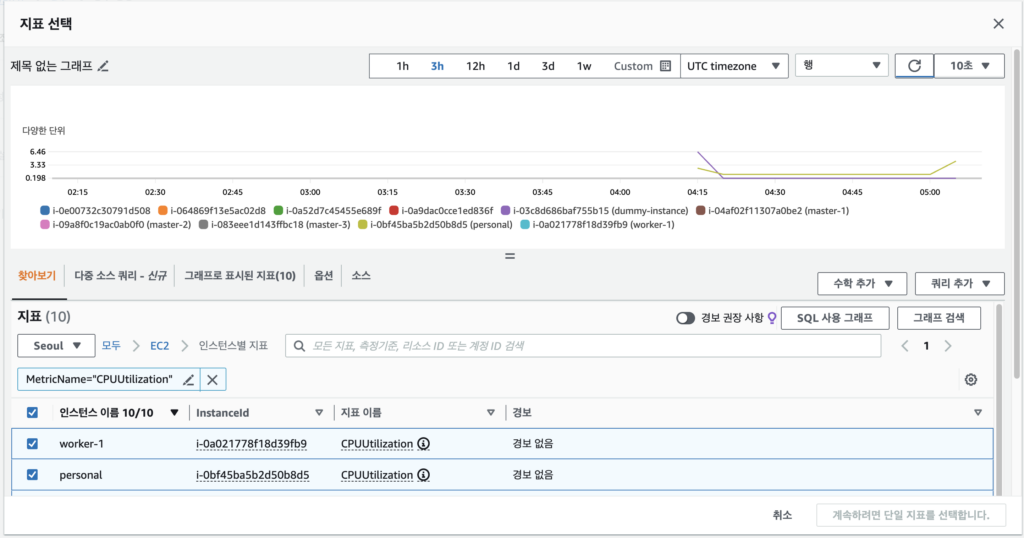
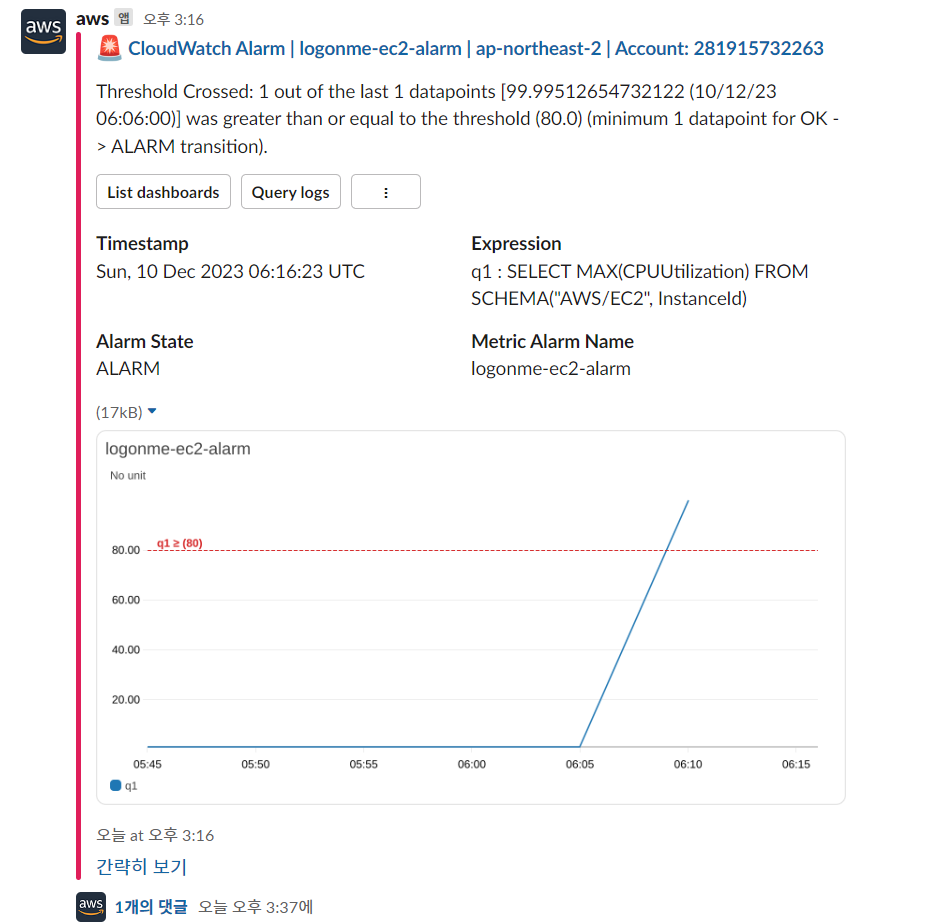
다음과 같이 2vpc/4GB Mem 스펙의 t3a.medium에서 CPU 사용량이 급증하는것을 볼 수 있다.

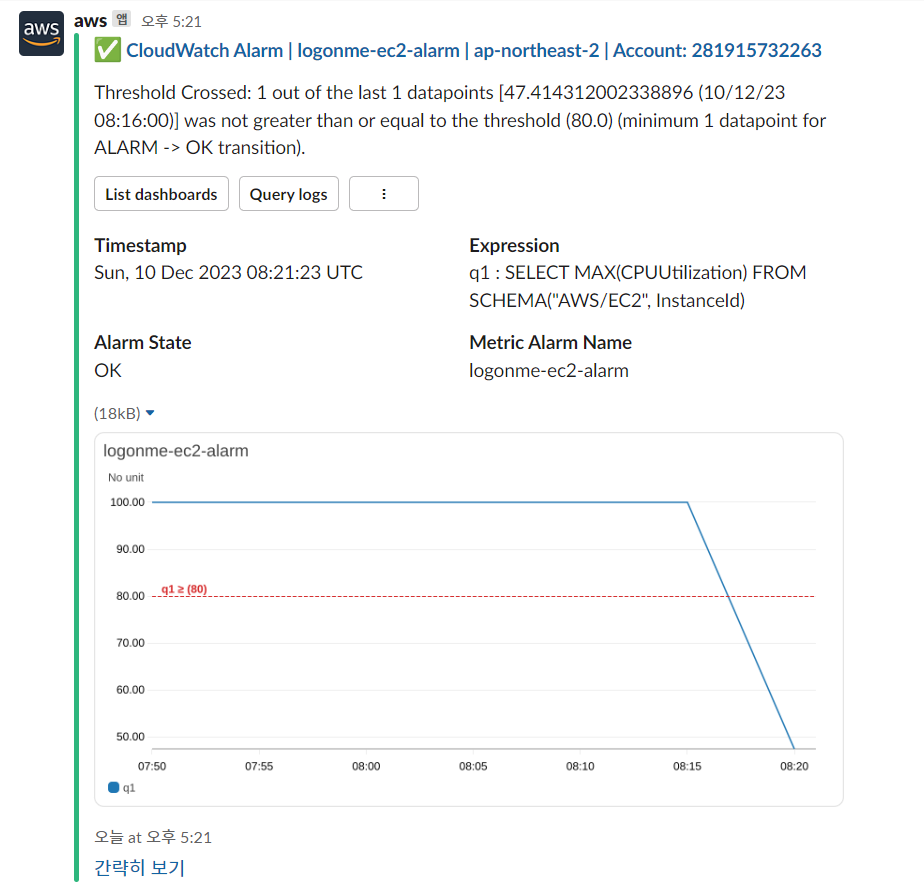
또한 약 5분 뒤, 슬랙 채널에 다음과 같이 AWS Chatbot 형식의 메세지와, Metric Graph가 첨부된 메세지가 수신되는것을 확인할 수 있다.
부하를 중단하면, 다음과 같이 상태가 OK로 전환되는다는 메세지를 수신할 수 있다.
Cloudwatch Dashboard 생성
알람 발생은 확인했지만, 위의 그래프 이미지에서도 확인할 수 있듯, 수학표현식을 통해 집계된 데이터는 최소한 1개의 인스턴스가 알람 상태에 있음을 확인할 수 있을뿐 정확히 몇개의 인스턴스가 장애상태인지, 어떤 인스턴스가 장애 상태인지 확인할 수 없다.
정확한 지표상태를 확인하기위해, CW Dashboard를 생성하고 chatbot에서 바로 대시보드를 조회할 수 있도록 설정할 것이다.
1. 사용자 대시보드 생성
AWS 웹 콘솔에서, Cloudwatch 서비스로 이동한 뒤 대시보드 탭으로 이동해 대시보드를 생성한다. 이름은 자유롭게 설정할 수 있고 default로 생성하였다
2. 위젯(데이터 소스) 추가
지표 그래프를 생성할 것이기 때문에, 데이터 유형을 지표로 그대로, 위젯 유형 또한 행으로 유지한다.
앞서 Cloudwatch 경보 생성시 사용하였던 쿼리문 뒤에, InstanceId별로 그룹화 한 뒤 내림차순으로 정렬한 상위 5개 인스턴스만 볼 수 있도록 설정할 것이다. (테스트시 5개까지 켜지 않아 2개만 조회됨)SELECT MAX(CPUUtilization) FROM SCHEMA("AWS/EC2", InstanceId) 에서SELECT MAX(CPUUtilization) FROM SCHEMA("AWS/EC2", InstanceId) GROUP BY InstanceId ORDER BY MAX() DESC LIMIT 5 으로 설정
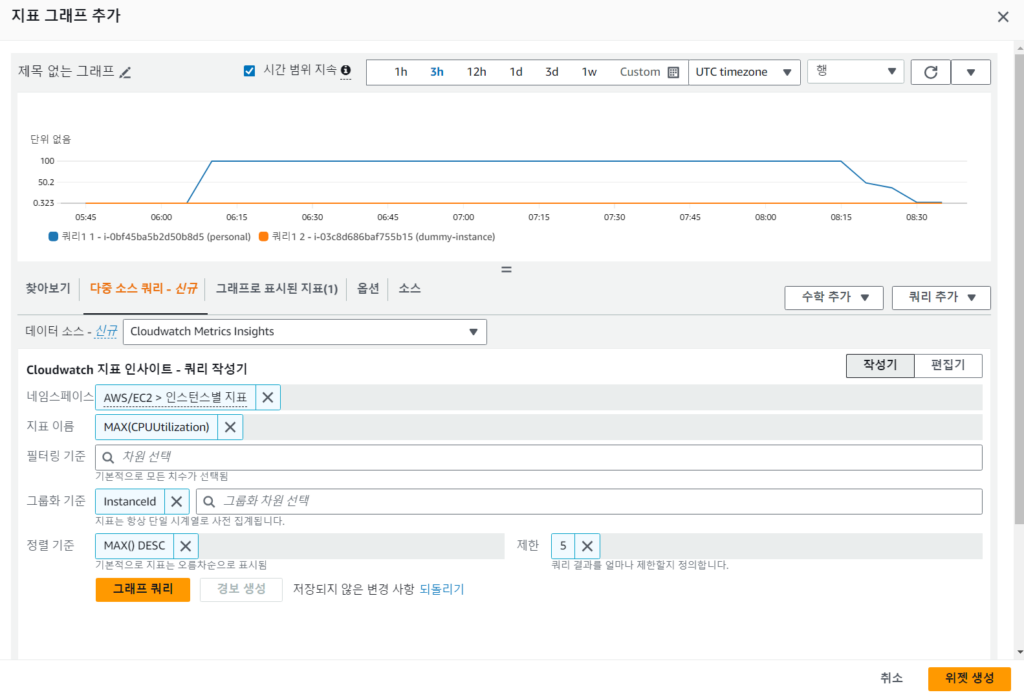
생성을 완료하면 다음과 같은 위젯을 확인할수 있고, InstanceId와 Name tag를 확인할 수 있다.
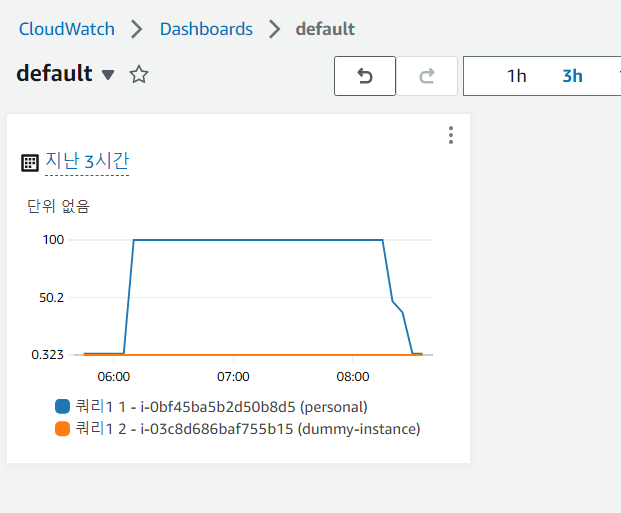
이제 Chatbot이 전송한 알람에서, List dashboads > default의 show > dropdown 메뉴에서 원하는 위젯 선택으로 위젯 정보를 Chatbot과의 인터랙션 대화를 통해 확인할 수 있다.
Outro
이러한 일련의 과정을 거쳐 ‘전체 AWS EC2 중, CPU 사용량 80% 이상인 인스턴스가 한대 이상 존재할 시, Slack 알람 수신’ 이라는 목적을 달성하였다.
Cloudwatch와 Chatbot 모두 AWS에서 제공하는 서비스인 만큼, 간단하게 구성할 수 있었지만 다음과 같은 아쉬움이 있었다
1. 실제 알람 대상을 확인하기 번거로움
위의 알람 확인 부분에서 확인할 수 있듯, 수학표현식 기반의 알람은 구체적인 알람 대상을 확인하기가 쉽지 않다. 이를 해결하기위해 별도의 Cloudwatch Dashboard 를 구성하고 위젯을 등록하였지만 알람 수신이후 별도의 상호작용을 하여야 하기 때문에 과정이 번거롭다. 그옆에 … 버튼을 통해 커스텀 액션을 지정할 수 있지만.. aws cli 명령어에 바로 widget을 보는 명령어는 없고, 조회할 시간을 전달하기가 쉽지않다.
2. Alarm message의 template 변경 불가
엄밀히 말하자면 Chatbot 메세지의 커스텀이 불가능한 것은 아니다. Custom notifications 문서를 확인해보면 custom notification/actions 등을 설정할 수 있지만 기존 메세지 형식을 수정하는 것이 아니라 event 형식부터 새로 만드는 것이기 간편히 구성한다는 목적과 상충한다(그럴바엔 Lambda 쓰지)
3. 알람의 현재상태를 지속적으로 파악하기 쉽지 않음
Cloudwatch Alarm은 State Change마다 Event가 발생하고 그 변경상태만을 전달한다.
위의 알람확인 같이 경보가 일정시간(1시간) 이상 지속되어도 최초의 state change 알람을 놓쳤을 경우 재경보 기능이 없어 대응에 실패할 수 있다.
4. 다수 인스턴스 등록 시, Alarm flickering 발생
OK > Alarm으로 가는 state의 데이터 포인트는 존재하지만, Alarm > OK의 state에 대한 데이터 포인트는 1/1로 고정되어있어 변경이 불가능하다.
다수의 인스턴스를 하나의 지표식으로 묶은 경우, 메트릭 전달과 반영의 딜레이가 있어 알람 평가기간은 5분이지만 제때 처리되지않아 상태가 짧게 OK로 전환되었다가 다시 Alarm으로 변경되는 경우도 있었다. 개인적으로는 Alarm flickering 이라고 부르긴 하는데.. 유사 사례도 못찾았고 해결방법 또한 찾지 못하였다.
위와같은 문제들로 인해, Cloudwatch + Chatbot 조합의 모니터링 알람체계는 포기하고 Lambda + Eventbridge 조합의 모니터링 알람체계를 구성하였다. 해당 알람 체계에 대한 구현기는 다음 글에서 정리하겠다.
참고 자료
AWS Chatbot과 슬랙(Slack)을 연동하여 AWS 명령 실행하기
[AWS] SNS. Chatbot을 활용해서 Slack으로 경보 보내기