CloudNet@팀에서 진행하는 쿠버네티스 실무 실습 스터디 참가글입니다.
24단계 실습으로 정복하는 쿠버네티스 도서 내용을 기반으로 진행됩니다.

1. Kubernetes 모니터링 및 로깅 시스템 구축
이번 챕터에서는, 시스템 운영에 있어서 필수적인 모니터링&로깅&알람 시스템을 위한 필요한 도구들을 알아보고, 실제로 구축해볼것입니다.
- 터미널에서 시스템 상태를 살펴볼 수 있는 k top, k9s
- 대시보드 & 알람 구축을 위한 프로메테우스, 그라파나, 얼럿매니저
- 중앙집중식 로깅 시스템을 위한 로키
실습 환경 배포
(Master – t3.small, Worker – c5a.2xlarge (AMD vCPU 8, Memory 16GiB)
# YAML 파일 다운로드
curl -O https://s3.ap-northeast-2.amazonaws.com/cloudformation.cloudneta.net/K8S/kops-oneclick-f1.yaml
# CloudFormation 스택 배포
aws cloudformation deploy –template-file kops-oneclick-f1.yaml –stack-name mykops –parameter-overrides KeyName=nasirk17 SgIngressSshCidr=$(curl -s ipinfo.io/ip)/32 MyIamUserAccessKeyID=$AWS_ACCESS_KEY_ID MyIamUserSecretAccessKey=$AWS_SECRET_ACCESS_KEY ClusterBaseName=$KOPS_CLUSTER_NAME S3StateStore=$KOPS_STATE_STORE MasterNodeInstanceType=t3.small WorkerNodeInstanceType=c5a.2xlarge –region ap-northeast-2
# CloudFormation 스택 배포 완료 후 kOps EC2 IP 출력
aws cloudformation describe-stacks –stack-name mykops –query ‘Stacks[*].Outputs[0].OutputValue’ –output text
# 13분 후 작업 SSH 접속
ssh -i ~/.ssh/nasirk17.pem ec2-user@$(aws cloudformation describe-stacks –stack-name mykops –query ‘Stacks[*].Outputs[0].OutputValue’ –output text)
# EC2 instance profiles 에 IAM Policy 추가(attach) : 처음 입력 시 적용이 잘 안될 경우 다시 한번 더 입력 하자! – IAM Role에서 새로고침 먼저 확인!
aws iam attach-role-policy –policy-arn arn:aws:iam::$ACCOUNT_ID:policy/AWSLoadBalancerControllerIAMPolicy –role-name masters.$KOPS_CLUSTER_NAME
aws iam attach-role-policy –policy-arn arn:aws:iam::$ACCOUNT_ID:policy/AWSLoadBalancerControllerIAMPolicy –role-name nodes.$KOPS_CLUSTER_NAME
# 메트릭 서버 확인 : 메트릭은 15초 간격으로 cAdvisor를 통하여 가져옴
kubectl top node
1.1 k top,k9s – k8s simple monitoring tool
터미널에서 간단히 클러스터 상태를 확인할 수 있는 명령어/도구로는 k top, k9s가 있다.
1.1.1. Metric server – resource usage check
Metrics Server는 Kubernetes에 내장된 자동 스케일링 파이프라인을 위한 확장 가능하고 효율적인 컨테이너 리소스 메트릭 소스입니다.
Kubernetes Metrics Server GitHub
Metrics Server는 Kubelet에서 리소스 메트릭을 수집하여 Horizontal Pod Autoscaler 및 Vertical Pod Autoscaler에서 사용할 수 있도록 Metrics API를 통해 Kubernetes 서버에 노출합니다. metrics API는 kubectl top에서도 액세스할 수 있으므로 자동 스케일링 파이프라인을 디버그하는 것이 더 쉽습니다.
메트릭 서버는 자동 확장이 아닌 용도로 제공되지 않습니다. 예를 들어 메트릭을 모니터링 솔루션으로 전달하거나 모니터링 솔루션 메트릭의 소스로 사용하지 마십시오. 이러한 경우 Kubelet/metrics/resource endpoint에서 직접 메트릭을 수집하십시오.
메트릭스 서버의 이점:
대부분의 클러스터에서 작동하는 단일 배포(요구사항 참조)
빠른 자동 확장, 매 15초마다 메트릭 수집.
클러스터의 각 노드에 대해 1밀리 코어의 CPU와 2MB의 메모리를 사용하는 리소스 효율성.
최대 5,000개 노드 클러스터까지 확장 가능한 지원.
기존 리눅스에서 top 명령어를 통해 리소스 사용량을 파악할 수 있듯, k8s 환경에서도 k top 명령어를 통해 각 노드/파드의 리소스 사용량을 파악할 수 있다. 다만 이를 위해서는 메트릭을 수집하는 metrics server 가 배포되어야 한다.
리소스 메트릭 파이프라인 아키텍쳐
kubernetes docs, 리소스 메트릭 파이프라인

해당 명령어의 작동 구조는 다음과 같다.
- kubelet의 cAdvisor: 컨테이너 메트릭을 수집, 집계, 노출하는 데몬
- 요약 API:
/stats엔드포인트를 통해 노드 별 요약된 정보를 탐색 및 수집 - Metrics-server: kubelet으로부터 수집한 리소스 메트릭을 수집 및 집계
- 메트릭 API: 오토스케일링에 사용되는 CPU 및 메모리 정보 제공 쿠버네티스 API
따라서 사용자가 k top 명령어를 입력하면, API Server는 해당 명령어를 Metrics server에 전달하고, 개별 노드에 실행된 kubelet의 cAdvisor가 노드/파드의 리소스 사용량을 수집하여 가져온다.
설치 및 환경셋팅에 대한 자세한 설명은 교재 및 위의 공식 Git 레포 참조.
명령어의 실행 결과는 다음과 같다.
# node metric 조회
[root@kops-ec2 ~]# k top node
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
i-0698876d363548da0 36m 0% 999Mi 6%
i-09196671c76d9dc01 34m 0% 1012Mi 6%
i-0a2a4938e1d5b5114 197m 9% 1253Mi 68%
# pod metric 조회
[root@kops-ec2 ~]# k top pod -n kube-system
NAME CPU(cores) MEMORY(bytes)
aws-cloud-controller-manager-wnhpm 3m 23Mi
aws-load-balancer-controller-6744dc7f67-pb4qp 2m 21Mi
aws-node-4zsr6 5m 25Mi
aws-node-7tnxw 3m 37Mi
aws-node-v4k49 3m 37Mi
cert-manager-9d894d6f-ctff6 1m 20Mi
cert-manager-cainjector-8659b5599b-26tnm 1m 16Mi
cert-manager-webhook-854dfb7d9-p749z 1m 10Mi
...
# pod memory 사용 순 정렬
[root@kops-ec2 ~]# k top pod -n kube-system --sort-by memory
NAME CPU(cores) MEMORY(bytes)
kube-apiserver-i-0a2a4938e1d5b5114 54m 342Mi
etcd-manager-main-i-0a2a4938e1d5b5114 23m 98Mi
kube-controller-manager-i-0a2a4938e1d5b5114 12m 55Mi
ebs-csi-controller-5778cfd49-dgf2n 2m 52Mi
aws-node-7tnxw 3m 37Mi
aws-node-v4k49 2m 37Mi
etcd-manager-events-i-0a2a4938e1d5b5114 10m 33Mi
aws-node-4zsr6 5m 25Mi
...k top 한계
k top은 노드와 파드의 CPU, MEM 리소스 조회는 가능하지만 서비스,디플로이 같은 그외의 리소스 / 시스템 메트릭 외의 로그 및 에러 조회등 클러스터 전반에 대한 모니터링은 부족하다. 클러스터 현황에 대한 자세한 정보는 아래 k9s CLI 를 통해 볼 수 있다.
1.1.2. k9s – k9s management CLI
k9s는 Kubernetes 클러스터와 상호 작용하기 위한 터미널 기반 UI입니다. 이 프로젝트의 목적은 배포된 애플리케이션을 보다 쉽게 탐색, 관찰 및 관리할 수 있도록 하는 것입니다. K9s는 지속적으로 Kubernetes의 변경 사항을 감시하고 관찰된 리소스와 상호 작용할 수 있는 후속 명령을 제공합니다.
k9s doc
설치는 공식 문서의 Install 참조 바람
# https://github.com/derailed/k9s/releases에서 바이너리 확인
wget https://github.com/derailed/k9s/releases/download/v0.27.3/k9s_Linux_amd64.tar.gz
tar -zxvf k9s_Linux_amd64.tar.gz
sudo mv ./k9s /usr/local/bin/k9sk9s을 실행시킨 뒤, ?를 입력하여 명령어 조회와 :를 입력하여 명령어를 입력할 수 있다.
메트릭 조회에 있어서, :pulses를 입력하여 deploy, rs, sts, ds 등 여러 리소스의 현황을 조회할 수 있다.

k9s의 모니터링 기능을 확인하기 위해, 에러가 발생하는 리소스를 배포해볼 것이다.
# 문제있는 deployment yaml 생성
kubectl create deployment my-dep --image=nginx --replicas=3 --dry-run=client -o yaml >> error.yaml
vi error.yaml
# L19~21
---
spec:
containers:
- image: ngiqweqweqweqweqweqwnx # 존재하지 않는 컨테이너 이미지
---
k apply -f error.yaml
위와 같이, 문제가 있는 리소스는 붉은 숫자로 카운트 되어있다.
이제 어떤 문제가 발생하고 있는지, 로그를 확인해볼것이다
- :deploy > deployment들 조회

- 방향키로 선택 후, 소문자 l (log 조회)

- esc로 빠져나와서, e (edit)으로 편집이 가능하다.
k9s이 없으면, 일일히 k get dep(탭)으로 리소스명 확인하고, k logs dep(탭) my-d(탭)해서 로그 조회한 뒤, k edit dep(탭) 이런식으로 매번 명령어를 입력하여야 할것이다.
k9s를 사용하면,:ns로 네임스페이스 고정 후, 방향키로 리소스 네비게이팅하면서 단순히 l(logs),d(describe),e(edit) 입력으로 명령어를 실행 가능하기 때문에 매우 유용하다.
k9s 한계
그러나 기본적으로 kube-system의 kube-apiserver의 상세 정보를 살펴보면 event-ttl이 1시간으로 설정되어있어 최대 1시간 내의 정보만 조회가 가능하다. 또한 네트워크 및 사용자 응답속도/커넥션 수와 같은 실제 애플리케이션 현황의 조회는 불가능하다. 이러한 정보는 이제 프로메테우스 같은 별도의 모니터링 시스템 구축이 필요하다.
1.2. Prometheus – k8s monitoring system
쿠버네티스에서 모니터링 시스템을 구축한다고 하면, 그 대상으로 교재에서는 다음의 3개의 대상을 권고한다. 내용을 간략히 정리하면 아래와 같다.
- 노드/파드 자원 사용량 모니터링
– 일반 가상 머신 환경과 유사
– 노드/파드의 CPU,Mem,N/W,Storage 등 - 클러스터 모니터링
– 클러스터 전반에 대한 모니터링
– k8s 오브젝트의 전체 수량, 종류 및 오브젝트 현황, 이벤트, 장애 발생 등 - 애플리케이션 모니터링
– 클러스터 구성요소 외에, 웹/DB/Product와 같은 애플리케이션
– 페이지 응답 속도, 세션 수, DB 쿼리 응답 속도 등
공식문서에서 연관 내용은 없나 찾아봤을때는 모니터링, 로깅 및 디버깅의 하위 문서들이 도움될 듯하다.
이러한 모니터링 시스템에 대해서 상용 솔루션 / 오픈소스 솔루션이 있으며, 그 중 오픈소스 솔루션인 프로메테우스를 알아볼 것이다.
Prometeus는 SoundCloud에 구축된 오픈 소스 시스템 모니터링 및 알림 툴킷입니다. 2012년 시작된 이래 많은 기업과 단체들이 Prometheus를 채택하고 있으며, 이 프로젝트는 매우 활발한 개발자와 사용자 커뮤니티를 가지고 있습니다. 이제는 독립적인 오픈 소스 프로젝트이며 어떤 회사와도 독립적으로 유지됩니다. 이를 강조하고 프로젝트의 거버넌스 구조를 명확히 하기 위해 Prometeus는 2016년에 Kubernetes에 이어 두 번째로 호스팅된 프로젝트로 Cloud Native Computing Foundation에 가입했습니다.
Promethus doc, OVERVIEW
Prometeus는 메트릭을 시계열 데이터로 수집 및 저장합니다. 즉, 메트릭 정보는 레이블이라고 하는 선택적 키-값 쌍과 함께 기록된 타임스탬프와 함께 저장됩니다.
주요 기능 (자세한 예시 및 설명은 교재 참조)
- a multi-dimensional data model with time series data identified by metric name and key/value pairs
- PromQL, a flexible query language to leverage this dimensionality
- no reliance on distributed storage; single server nodes are autonomous
- time series collection happens via a pull model over HTTP
- pushing time series is supported via an intermediary gateway
- targets are discovered via service discovery or static configuration
- multiple modes of graphing and dashboarding support
1.2.1. Architecture

- Prometheus target(Node exporter) > 노드에서, pull 방식 메트릭 수집
- Push gateway > 일회성 작업 (Short-lived jobs)를 통한 메트릭 수집
- Prometheus server > 시계열데이터(TS, time series) 수집 및 저장(TSDB)
- Alertmanager > 경보 설정 및 트리거
- Prometheus web UI > 프로메테우스 웹 대시보드
작동 방식
- Node exporter(Pull) / Pushgateway(job)이 메트릭 수집
- Prometheus server가 메트릭 집계 후 TSDB(Time Series DataBase)에 저장
- PromQL을 통해 저장된 TSdata 조회, web UI나 Grafana와 연계한 시각화
- server가 경보감지하면 Alertmanager가 이메일, 슬랙 등으로 경보 전파
1.2.2. Prometheus stack Helm installation
말은 간단히 ‘프로메테우스를 사용한 모니터링 시스템’이지만, 실제로 구축하는 과정에서는 필요한 dependency나, 같이 구성하면 좋은 도구들이 존재한다.
https://artifacthub.io/packages/helm/prometheus-community/kube-prometheus-stack
k8s의 패키지 매니저라고 할 수 있는 Helm에는, 해당 구성을 묶어놓은 stack들이 Helm chart 형식으로 존재한다. 따라서 커스텀이 필요한 값들만 value로 생성해 차트로 던져주면, 자동으로 deploy, svc, cm, sa, 등의 구성을 잡아주고 서비스가 구성된다.
kube-prometheus-stack 구성 및 설치
# 모니터링
kubectl create ns monitoring
watch kubectl get pod,pvc,svc,ingress -n monitoring
# 사용 리전의 인증서 ARN 확인
CERT_ARN=`aws acm list-certificates –query ‘CertificateSummaryList[].CertificateArn[]’ –output text`
echo “alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN”
# 설치
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
# 파라미터 파일 생성
cat <<EOT > ~/monitor-values.yaml
alertmanager:
ingress:
enabled: true
ingressClassName: alb
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/listen-ports: ‘[{“HTTPS”:443}, {“HTTP”:80}]’
alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
alb.ingress.kubernetes.io/success-codes: 200-399
alb.ingress.kubernetes.io/group.name: “monitoring”
hosts:
– alertmanager.$KOPS_CLUSTER_NAME
paths:
– /*
grafana:
defaultDashboardsTimezone: Asia/Seoul
adminPassword: prom-operator
ingress:
enabled: true
ingressClassName: alb
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/listen-ports: ‘[{“HTTPS”:443}, {“HTTP”:80}]’
alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
alb.ingress.kubernetes.io/success-codes: 200-399
alb.ingress.kubernetes.io/group.name: “monitoring”
hosts:
– grafana.$KOPS_CLUSTER_NAME
paths:
– /*
prometheus:
ingress:
enabled: true
ingressClassName: alb
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/listen-ports: ‘[{“HTTPS”:443}, {“HTTP”:80}]’
alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
alb.ingress.kubernetes.io/success-codes: 200-399
alb.ingress.kubernetes.io/group.name: “monitoring”
hosts:
– prometheus.$KOPS_CLUSTER_NAME
paths:
– /*
prometheusSpec:
podMonitorSelectorNilUsesHelmValues: false
serviceMonitorSelectorNilUsesHelmValues: false
retention: 5d
retentionSize: “10GiB”
EOT
# 배포
helm install kube-prometheus-stack prometheus-community/kube-prometheus-stack –version 45.7.1 \
–set prometheus.prometheusSpec.scrapeInterval=’15s’ –set prometheus.prometheusSpec.evaluationInterval=’15s’ \
-f monitor-values.yaml –namespace monitoring
# 확인
## alertmanager-0 : 사전에 정의한 정책 기반(예: 노드 다운, 파드 Pending 등)으로 시스템 경고 메시지를 생성 후 경보 채널(슬랙 등)로 전송
## grafana : 프로메테우스는 메트릭 정보를 저장하는 용도로 사용하며, 그라파나로 시각화 처리
## prometheus-0 : 모니터링 대상이 되는 파드는 ‘exporter’라는 별도의 사이드카 형식의 파드에서 모니터링 메트릭을 노출, pull 방식으로 가져와 내부의 시계열 데이터베이스에 저장
## node-exporter : 노드익스포터는 물리 노드에 대한 자원 사용량(네트워크, 스토리지 등 전체) 정보를 메트릭 형태로 변경하여 노출
## operator : 시스템 경고 메시지 정책(prometheus rule), 애플리케이션 모니터링 대상 추가 등의 작업을 편리하게 할수 있게 CRD 지원
## kube-state-metrics : 쿠버네티스의 클러스터의 상태(kube-state)를 메트릭으로 변환하는 파드
helm list -n monitoring
kubectl get pod,svc,ingress -n monitoring
kubectl get-all -n monitoring
kubectl get prometheus,alertmanager -n monitoring
kubectl get prometheusrule -n monitoring
kubectl get servicemonitors -n monitoring
kubectl get crd | grep monitoring
1.2.3. Function/Usage
- 모니터링 대상이 되는 서비스는 일반적으로 자체 웹 서버의 /metrics 엔드포인트 경로에 다양한 메트릭 정보를 노출
- 이후 프로메테우스는 해당 경로에 http get 방식으로 메트릭 정보를 가져와 TSDB 형식으로 저장
# 아래 처럼 프로메테우스가 각 서비스의 9100 접속하여 메트릭 정보를 수집
kubectl get node -owide
kubectl get svc,ep -n monitoring kube-prometheus-stack-prometheus-node-exporter
# NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
# service/kube-prometheus-stack-prometheus-node-exporter ClusterIP 100.71.12.100 <none> 9100/TCP 9m32s
# NAME ENDPOINTS AGE
# endpoints/kube-prometheus-stack-prometheus-node-exporter 172.30.38.137:9100,172.30.55.65:9100,172.30.85.158:9100 9m32s
# 마스터노드에 lynx 설치
ssh -i ~/.ssh/id_rsa ubuntu@api.$KOPS_CLUSTER_NAME hostname
ssh -i ~/.ssh/id_rsa ubuntu@api.$KOPS_CLUSTER_NAME sudo apt install lynx -y
# 노드의 9100번의 /metrics 접속 시 다양한 메트릭 정보를 확인할수 있음 : 마스터 이외에 워커노드도 확인 가능
ssh -i ~/.ssh/id_rsa ubuntu@api.$KOPS_CLUSTER_NAME lynx -dump localhost:9100/metrics- web UI 접속
# ingress 확인
kubectl get ingress -n monitoring kube-prometheus-stack-prometheus
kubectl describe ingress -n monitoring kube-prometheus-stack-prometheus
# 프로메테우스 ingress 도메인으로 웹 접속
echo -e "Prometheus Web URL = https://prometheus.$KOPS_CLUSTER_NAME"
# 웹 상단 주요 메뉴 설명
1. 경고(Alert) : 사전에 정의한 시스템 경고 정책(Prometheus Rules)에 대한 상황
2. 그래프(Graph) : 프로메테우스 자체 검색 언어 PromQL을 이용하여 메트릭 정보를 조회 -> 단순한 그래프 형태 조회
3. 상태(Status) : 경고 메시지 정책(Rules), 모니터링 대상(Targets) 등 다양한 프로메테우스 설정 내역을 확인 > 버전(2.42.0)
4. 도움말(Help)
web UI를 통한 prometheus의 config 조회 및 편집등은 교재 참조 바람
저장된 시계열 데이터를 조회하는 쿼리문 작성에 있어서, 기본적으로 autocomplete이 활성화 되어있다. 따라서 PromQL을 잘 모르더라도, 기본적인 단어 기반으로 메트릭을 쿼리하고, 프로메테우스 수준의 그래프를 조회해 볼 수 있다.

node / kube 등을 입력하면 해당 단어를 시작으로 조회할 수 있는 metric 값이 autocomplete로 제안되고, 우측에 해당 메트릭의 의미에 대한 설명이 제공된다.
또는 쿼리 입력칸 우측의 지구본모양(open Metrics Explorer)를 통해 조회할수 있는 metric의 목록을 볼 수 있다.
상단 탭 중 Table은 쿼리 결과를 표로 제공하고,(상단의 그래프 아래부분) Graph는 쿼리 결과를 그래프로 제공해준다.
교재에서는 1- avg(rate(node_cpu_seconds_total{mode="idle"}[1m])) 과 같이 몇가지 쿼리문의 예시와, 의미에 대한 설명이 수록되어 있다.
프로메테우스 시각화의 한계
위의 그림과 같이, prometheus web UI도 쿼리문에 대한 그래프를 제공해준다. 그러나 한번에 하나의 쿼리문에 대한 결과만을 조회할 수 있다. 여러 쿼리문에 대한 결과를 한꺼번에 보거나, 선 그래프 대신 도넛/바 그래프와 같은 다른 유형의 그래프를 보려면 전문적인 시각화 대시보드가 필요할것이다 > 그라파나로 이어짐
1.3. Grafana – k8s monitoring visualization
Grafana 오픈 소스 소프트웨어를 사용하면 메트릭, 로그 및 트레이스가 저장된 위치에서 쿼리, 시각화, 경고 및 탐색할 수 있습니다. Grafana OSS는 TSDB(시계열 데이터베이스) 데이터를 통찰력 있는 그래프 및 시각화로 변환하는 도구를 제공합니다.
Grafana docs, Introduction to Grafana
위의 설명과 같이, 그라파나는 TSDB(시계열 데이터베이스) 데이터를 그래프 및 시각화 하는 도구이다.
그라파나는 일반적인 소프트웨어 개발로 쳤을때 프론트엔드에 해당하지않을까? 하는 생각을 한다. 그라파나 자체로는 특별히 데이터를 저장하거나 처리하지는 않고, Datasoure를 통해 접근한 데이터에 대한 그래프등을 대시보드화 하여 제공한다.
- Time series databases
- Prometheus
- Graphite
- InfluxDB
- OpenTSDB
- Logging & document databases
- Loki
- Elasticsearch
- Distributed tracing
- Jaeger
- Tempo
- Zipkin
- SQL
- MySQL
- PostgreSQL
- Microsoft SQL Server
- Cloud
- Azure Monitor
- AWS CloudWatch
- Google Cloud Monitoring
- Grafana Cloud
- Enterprise plugins
- AppDynamics
- Azure Devops
- DataDog
- Dynatrace
- GitLab
- Honeycomb
- Jira
- MongoDB
- New Relic
- Oracle
- SAP HANA
- Salesforce
- Snowflake
- Splunk
- Splunk Infastructure Monitoring
- Wavefront
- Others
- Alertmanager
- TestData DB
1.3.1. Helm installation
1.2.2.의 Prometheus stack Helm installation시 같이 구성되어 설치되어있다.
Grafana 접근 정보 확인
# ingress 확인
kubectl get ingress -n monitoring kube-prometheus-stack-grafana
kubectl describe ingress -n monitoring kube-prometheus-stack-grafana
# ingress 도메인으로 웹 접속
echo -e “Grafana Web URL = https://grafana.$KOPS_CLUSTER_NAME”
# 기본 계정 – admin / prom-operator
1.3.2. Dashboard

접속 후 좌측의 < 를 누르면 메뉴가 확대되어 나타난다
- Search dashboards : 대시보드 검색
- Starred : 즐겨찾기 대시보드
- Dashboards : 대시보드 전체 목록 확인
- Explore : 쿼리 언어 PromQL를 이용해 메트릭 정보를 그래프 형태로 탐색
- Alerting : 경고, 에러 발생 시 사용자에게 경고를 전달
- Configuration : 설정, 예) 데이터 소스 설정 등
- Server admin : 사용자, 조직, 플러그인 등 설정
- admin : admin 사용자의 개인 설정
대시보드 구성
좌측의 Dashboards > Browse를 클릭하면, General 폴더 안에 기본 대시보드들이 있다.
- Overview
- Cluster 관련 등
- Node 관련 등
- Network 관련 등
기본 대시보드 외에, 그라파나 공식 홈페이지에서는 공유 템플릿 대시보드를 제공한다.
해당 페이지에서 다른 사용자들이 사전 설정해놓은 대시보드 양식을 조회할 수 있고,(23년 4월 기준 약 6400여개) 대시보드 ID번호나 JSON을 받아서 import 할수 있다.
- 좌측의 Dashboards > + Import 클릭
- Import via grafana.com에 ID 입력 또는 Import via panel json에 json 입력
- 한국어 대시보드로는 13770이 유명
- 불러온 대시보드와 연결할 Datasource 선택 후 import

1.3.3. Function/Usage
NGINX 웹서버 배포 및 애플리케이션 모니터링 설정 및 접속
기본 어플리케이션 외에, 사용자가 직접 설치한 앱의 모니터링을 수행해본다.

서비스 모니터는 Prometheus Operator가 사용하는 CRD(Custom Resource Definion)이다. 해당 CRD를 통해, 프로메테우스의 설정 변경없이 새로운 모니터링 대상의 등록 및 추적이 가능하다.
nginx web service
# repo 추가
helm repo add bitnami https://charts.bitnami.com/bitnami
# 파라미터 파일 생성 : 서비스 모니터 방식으로 nginx 모니터링 대상을 등록하고, export 는 9113 포트 사용, nginx 웹서버 노출은 AWS CLB 기본 사용
cat <<EOT > ~/nginx-values.yaml
metrics:
enabled: true
service:
port: 9113
serviceMonitor:
enabled: true
namespace: monitoring
interval: 10s
EOT
# 배포
helm install nginx bitnami/nginx –version 13.2.23 -f nginx-values.yaml
# CLB에 ExternanDNS 로 도메인 연결
kubectl annotate service nginx “external-dns.alpha.kubernetes.io/hostname=nginx.$KOPS_CLUSTER_NAME”
# 확인
kubectl get pod,svc,ep
kubectl get servicemonitor -n monitoring nginx
kubectl get servicemonitor -n monitoring nginx -o json | jq
# nginx 파드내에 컨테이너 갯수 확인
kubectl get pod -l app.kubernetes.io/instance=nginx
kubectl describe pod -l app.kubernetes.io/instance=nginx
# 접속 주소 확인 및 접속
echo -e “Nginx WebServer URL = http://nginx.$KOPS_CLUSTER_NAME”
curl -s http://nginx.$KOPS_CLUSTER_NAME
kubectl logs deploy/nginx -f
# 반복 접속
while true; do curl -s http://nginx.$KOPS_CLUSTER_NAME -I | head -n 1; date; sleep 1; done
배포 완료 후, 프로메테우스 웹 > Status > Targets에 nginx의 등록 확인 가능

12708 대시보드를 통해 nginx에 대한 대시보드 구성 가능

그라파나 대시보드의 한계
시각화된 대시보드를 통해 클러스터 현황에 대한 가시성이 확보되었다. 그러나 별도의 모니터링/관제 인력이 있는게 아니라면, 클러스터 상태를 항상 지켜볼 수는 없다.
장애는 언제 발생할지 모른다. 잠시 자리를 비운사이 발생할 수도 있고, 업무 시간 이후 퇴근 후에 발생할 수도, 주말에 발생할 수도 있다. 물론 쿠버네티스는 self healing 능력이 있기 때문에 일부파드가 다운되어도 재시작하거나, 노드 가용성이 떨어지면 추가 노드를 배치하는등 자동화된 대응이 가능하다. 그렇지만 운영인력은 장애가 발생했었는지, 원인은 무엇이였는지에 대해 인지할 수 있어야 한다.
따라서 운영이 특정 이벤트(장애 위험/발생/해결 등)를 인지할수 있도록, 적절한 채널을 통한 경보 기능이 필요할 것이다.
1.4. Alert Manager – k8s monitoring alert
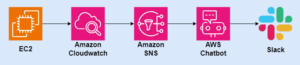
Prometheus를 사용한 경고는 두 부분으로 나뉩니다. Prometeus 서버의 알림 규칙은 Alertmanager에게 알림을 보냅니다. 그런 다음 Alertmanager는 전자 메일, 전화 경보 및 채팅 플랫폼과 같은 방법을 통해 알림을 전파하거나, 일시정지, 중지, 통합등과 같이 알림을 관리합니다.
Prometheus Alerting Overview

프로메테우스는 경고 관리를 Alertmanager로 별도로 관리합니다. 프로메테우스 서버가 설정된 임곗값 도달 시 경고 메시지를 얼럿매니저에 푸시 이벤트로 전달하고, 얼럿매지저는 이를 가공후 이메일/슬랙 등에 전달합니다. (링크)
1.4.1. Alertmanager & Karma 시스템 경보
프로메테우스 경고 규칙 상태 확인

먼저 프로메테우스 웹 UI에서, 상단의 Alerts를 클릭하여 경고 상태를 확인할 수 있다.
시스템 경고 정책은 prometheusrules CRD로 관리되며, 아래의 3가지 단계가 있다
- Inactive 비활성화 : prometheusrules 중 경고가 활성화되지 않은 정상적인 상태
- Pending 지연 : 설정한 임곗값을 초과해 경고 상황이지만 경고 메시지를 전달하기까지 임곗값 시간을 초과하지 않은 상태, 이를 통해 오탐과 자동 복구된 에러 메시지를 처리
- Firing 경보 : 임곗값과 임곗값 시간을 초과해서 경보가 발생한 메시지. 해당 메시지는 얼럿매니저에 전달되어 얼럿매지저를 통해 전파됨
상단의 태그버튼을 통해, 원하는 수준의 경고만 볼 수 있도록 필터링 할 수 있다
경고 규칙 중, general.rules의 탐지견(watchdog) 경고는 항상 발생상태이다. 실제 장애와 별개로 얼럿매니저의 정상 작동 여부를 확인하는 용도로 사용된다.
Karma
Alert dashboard for Prometheus Alertmanager.
Alertmanager UI는 경고를 검색하고 일시정지를 관리하는 데 유용하지만 대시보드 도구로는 부족합니다. 카르마는 이 공백을 메우는 것을 목표로 합니다.
Karma github
Karma는 Alertmanager UI를 개선하고, 시각화하는 도구이다.
Karma docker 실행 및 접속
# 실행
docker run -d -p 80:8080 -e ALERTMANAGER_URI=https://alertmanager.$KOPS_CLUSTER_NAME ghcr.io/prymitive/karma:latest
# 확인
docker ps
# 접속
echo -e “karma Web URL = http://$(aws cloudformation describe-stacks –stack-name mykops –query ‘Stacks[*].Outputs[0].OutputValue’ –output text)”

Karma에서 또한 동일하게 4개의 경고가 경보중인것을 볼 수 있다.
얼럿매니저 웹 접속
# ingress 도메인으로 웹 접속
echo -e "Alertmanager Web URL = https://alertmanager.$KOPS_CLUSTER_NAME"
- Alerts 경고: 시스템 문제 시 프로메테우스가 전달한 경고 메시지 목록을 확인
- Silences 일시 중지 : 계획 된 장애 작업 시 일정 기간 동안 경고 메시지를 받지 않을 때, 메시지별로 경고 메시지를 일시 중단 설정
- Statue 상태 : 얼럿매니저 상세 설정 확인
1.4.2. Slack Webhook URL 생성
위에서 살펴보았듯, 작동중인 경고를 받으려면 적절한 수신처가 필요하다. 메세지를 수신할 슬랙 채널을 생성하고, webhook URL을 생성할 것이다.
- 슬랙에서 새로운 채널을 생성하고, 채널 우클릭 > 채널 세부정보 보기 > 통합 > 앱 내 앱 추가
- Incomming webhook(수신 웹 후크 추가) 선택 후 채널에 추가(또는 구성) > 채널에 포스트 에서 메세지를 받을 채널 선택
해당 단계를 수행하면 채널과 연동된 웹훅 URL을 생성할 수 있다

웹훅은 보통 만들고 까먹기 때문에, 채널 설명등에 적어두면 나중에 바로 조회할 수 있다.
1.4.3. Verification
위에 생성한 Slack webhook으로, 실제 경보 메세지를 수신할 수 있는지 확인할 것이다.
# alertmanager에 웹훅 URL 업데이트
alertmanager:
config:
global:
resolve_timeout: 5m
slack_api_url: 'https://hooks.slack.com/services/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'
route:
group_by: ['job'] # namespace
group_wait: 10s
group_interval: 1m
repeat_interval: 5m
receiver: 'slack-notifications'
routes:
- receiver: 'slack-notifications'
matchers:
- alertname =~ "InfoInhibitor|Watchdog"
receivers:
- name: 'slack-notifications'
slack_configs:
- channel: '#pkos'
send_resolved: true
title: '[{{.Status | toUpper}}] {{ .CommonLabels.alertname }}'
text: |
*Description:* {{ .CommonAnnotations.description }}
# helm 업그레이드로 얼럿매니저에 웹훅 URL 정보 반영
helm upgrade kube-prometheus-stack prometheus-community/kube-prometheus-stack --reuse-values -f alertmanager-slack.yaml --namespace monitoring얼럿매니저 웹 → Status : 아래 config 부분에 위 슬랙 정보, 타이머 정보 확인

- 슬랙 연동이 완료되어 채널에 메세지 수신된 모습
현재 2개의 장애(경보) 이슈 해결 : kube-controller-manager, kube-scheduler
프로메테우스 웹 → Status → Targets 확인 : kube-controller-manager, kube-scheduler 없음 확인
# 레이블 셀렉터 Selector 정보 확인!
kubectl get svc,ep -n kube-system kube-prometheus-stack-kube-controller-manager
kubectl describe svc -n kube-system kube-prometheus-stack-kube-controller-manager
# kube-controller-manager 파드의 레이블 확인
kubectl get pod -n kube-system --show-labels | grep kube-controller-manager
# 레이블 셀렉터 Selector 정보 확인!
kubectl get svc,ep -n kube-system kube-prometheus-stack-kube-scheduler
kubectl describe svc -n kube-system kube-prometheus-stack-kube-scheduler
# 파드의 레이블 확인
kubectl get pod -n kube-system --show-labels | grep kube-scheduler파드에 레이블 추가하여 해결하기
# 추가
kubectl label $(kubectl get pod -n kube-system -l k8s-app=kube-controller-manager -oname) -n kube-system component=kube-controller-manager
# 확인
kubectl get svc,ep -n kube-system kube-prometheus-stack-kube-controller-manager
# 추가
kubectl label $(kubectl get pod -n kube-system -l k8s-app=kube-scheduler -oname) -n kube-system component=kube-scheduler
# 확인
kubectl get svc,ep -n kube-system kube-prometheus-stack-kube-scheduler해당 레이블을 추가하면, 프로메테우스 웹 Status → Targets 에서 kube-controller-manager, kube-scheduler 두 타겟이 등록되고, 프로메테우스 웹 Alerts에서도 사라진것을 확인할 수 있다.


Alert 시스템의 한계
경고 시스템을 통해서 인지하지 못하는 순간에 발생한 장애에 대해서 사후적으로 인지할 수 있게 되었다.
그렇지만 종료된 파드의 로그는 파드 종료와 함께 사라지기 때문에 장애 이후 원인 파악하는데 어려움을 겪을 수 있다. 또한 kubelet의 기본 설정에서, 로그 파일의 최대 크기는 10Mi이기 때문에 장기적으로 가동중이여서 로그 파일이 커질 경우, 전체 로그 조회는 불가능하다. 따라서 파드에 개별적으로 남는 로그 외에도, 별도의 솔루션을 통해 로그 수집 시스템을 갖춰야 할것이다 > 는 로키
1.5. Loki – k8s logging system
Grafana Loki는 완전한 기능을 갖춘 로깅 스택으로 구성할 수 있는 구성 요소 집합입니다.
Grafana Loki
다른 로깅 시스템과 달리 Loki는 로그에 대한 메타데이터(프로메테우스 레이블과 동일)만 인덱싱하는 아이디어를 바탕으로 구축되었습니다. 그러면 로그 데이터 자체가 압축되어 S3 또는 GCS와 같은 개체 저장소에 청크로 저장되거나 파일 시스템의 로컬에 저장됩니다. 인덱스가 작고 압축도가 높은 청크를 사용하면 작업이 간소화되고 로키의 비용이 크게 절감됩니다.

- Loki에 저장한 로그는 LogQL(PromQL과 유사)을 이용해 조회 할 수 있으며, 그라파나 웹이나 logcli를 이용해 조회 가능
- 전체 로그 기반 인덱스를 생성하지 않고, 메타데이터를 기준으로 인덱스를 생성하여 자원 사용량이 현저히 적음
컨테이너 로그 환경의 로그는 표준 출력 stdout과 표준 에러 stderr로 보내는 것을 권고
- A cloud-native application writes all of its log entries to
stdoutandstderr - 수백개 앱의 개발과 배포에 직접 참여했으며, Heroku 플랫폼을 통해서 방대한 앱의 개발, 운영, 확장을 간접적으로 관찰한 사람들이 12-factor app 방법론 제시
- 11번째 항목 로그에 있어서, 위와 같은 권고 사항이 존재
- 해당 권고에 따라 작성된 컨테이너 애플리케이션의 로그는 해당 파드 안으로 접속하지 않아도 사용자는 외부에서 kubectl logs 명령어로 애플리케이션 종류에 상관없이,애플리케이션마다 로그 파일 위치에 상관없이, 단일 명령어로 조회 가능
# 로그 모니터링
kubectl logs deploy/nginx -c nginx -f
# nginx 컨테이너 로그 파일 위치 확인
kubectl exec -it deploy/nginx -c nginx -- ls -l /opt/bitnami/nginx/logs/
# total 0
# lrwxrwxrwx 1 root root 11 Jan 23 12:15 access.log -> /dev/stdout
# lrwxrwxrwx 1 root root 11 Jan 23 12:15 error.log -> /dev/stderrWhat is PLG Stack (Promtail, Loki and Grafana)?

PLG Stack > Promtail + Loki + Grafana
- Promtail이 여러 파드의 로그들을 수집
- Loki가 중앙 서버에 저장하고 이를 조회
- Grafana를 통한 로그 시각화
1.5.1. Helm install
Helm에 존재하는 grafana 차트의 loki와, promtail을 각각 설치할 것이다
Loki install
# 모니터링
kubectl create ns loki
watch kubectl get pod,pvc,svc,ingress -n loki
# Repo 추가
helm repo add grafana https://grafana.github.io/helm-charts
# 파라미터 설정 파일 생성
cat <<EOT > ~/loki-values.yaml
persistence:
enabled: true
size: 20Gi
serviceMonitor:
enabled: true
EOT
# 배포
helm install loki grafana/loki –version 2.16.0 -f loki-values.yaml –namespace loki
# 설치 확인 : 데몬셋, 스테이트풀셋, PVC 확인
helm list -n loki
kubectl get pod,pvc,svc,ds,sts -n loki
kubectl get-all -n loki
kubectl get servicemonitor -n loki
kubectl krew install df-pv && kubectl df-pv
# curl 테스트 용 파드 생성
kubectl apply -f ~/pkos/2/netshoot-2pods.yaml
# 로키 gateway 접속 확인
kubectl exec -it pod-1 — curl -s http://loki.loki.svc:3100/api/prom/label
# (참고) 삭제 시
helm uninstall loki -n loki
kubectl delete pvc -n loki –all
Promtail install
# 파라미터 설정 파일 생성
cat <<EOT > ~/promtail-values.yaml
serviceMonitor:
enabled: true
config:
serverPort: 3101
clients:
– url: http://loki-headless:3100/loki/api/v1/push
EOT
# 배포
helm install promtail grafana/promtail –version 6.0.0 -f promtail-values.yaml –namespace loki
# (참고) 파드 로그는 /var/log/pods에 저장
ssh -i ~/.ssh/id_rsa ubuntu@api.$KOPS_CLUSTER_NAME ls /var/log/pods
# 설치 확인 : 데몬셋, 스테이트풀셋, PVC 확인
helm list -n loki
kubectl get pod,pvc,svc,ds,sts,servicemonitor -n loki
kubectl get-all -n loki
# (참고) 삭제 시
helm uninstall promtail -n loki
1.5.2. Function/Usage
Datasoure 추가
- 그라파나 → Configuration → Data Source : 데이터 소스 추가 ⇒ Loki 클릭
- HTTP URL : http://loki-headless.loki:3100 ⇒ Save & Test

nginx 반복 접속
# 접속 주소 확인 및 접속
kubectl logs deploy/nginx -f
# 반복 접속
while true; do curl -s http://nginx.$KOPS_CLUSTER_NAME -I | head -n 1; date; sleep 1; done접근 기록 로그 조회
- 그라파나 → Explore : 상단 데이터 소스 Loki 선택
- Logfilters : Job → default/nginx 값 선택 ⇒ 우측 상단 Run query 클릭
- 임의의 로그 클릭 : 상세 정보 확인 – 파드 레이블, 네임스페이스, 잡 등 전체 로그 레이블 확인 가능

Loki 로그 확인 대시보드 : 15141

3. 마무리
- 더 나은 해결책을 찾기 위한 노력
- 도구 공부해서 메트릭 수집했다/시각화했다/경고 메세지 보냈다도 재밌지만
- 왜 수집/시각화/메세지/로깅해야해? 하고 이유 생각하는것도 즐거움
- 이번 파트 보다보니, 단계별로 한계점이 있었고, 해결책 제시가 보여서 재밌었음
- 명령어로 CPU,Mem보기
- CLI 도구로 더 많은 System metric 보기
- 모니터링 시스템으로 클러스터 상태 수집 & 저장
- 시각화 도구로 저장된 클러스터 상태 깔끔하게 & 여러개 보기
- 경고 시스템으로 대시보드 안봐도 알수있게하기
- 중앙로깅으로 사라진 기록 아카이빙하기
- Helm list에서 배포된 chart가 사라지는 오류
- helm upgrade kube-prometheus-stack prometheus-community/kube-prometheus-stack –reuse-values -f alertmanager-slack.yaml –namespace monitoring
- 얼럿 매니저 설정 업그레이드 하던 도중 Unable to connect to the server: net/http: TLS handshake timeout” from kubectl 에러 발생
- 해당에러 자체는 업그레이드도중 컨트롤노드 리소스 부족해서 발생한듯함
- 발생 이후 helm list에서 배포된 차트가 사라짐
- terraform 배포 다하고 state파일 잃어버린 듯한 느낌

- helm은 과거 revision을 저장하는가 / 형상 관리가 어떻게 수행되는가?
- secrets의 형태로 과거 형상을 저장하고 있음 (링크)
- manifest가 secret으로 가면서 base64 인코딩
- helm이 secret을 다시 한번 base64 인코딩
- gzip 압축되어있는것을 압축 해제
- secrets의 형태로 과거 형상을 저장하고 있음 (링크)
# 현재 버전의 manifest 조회
# helm get 으로는 현재 버전만 가져올 수 있음
helm get manifest kube-prometheus-stack -n monitoring
# 과거 버전의 정보는 k8s secrets로 저장되어 있음
k get secrets -n monitoring
# NAME TYPE DATA AGE
# sh.helm.release.v1.kube-prometheus-stack.v1 helm.sh/release.v1 1 84m
# sh.helm.release.v1.kube-prometheus-stack.v2 helm.sh/release.v1 1 80m
# 바로 조회시 난수화
kubectl get secrets sh.helm.release.v1.kube-prometheus-stack.v1 -o json
# "data": {
# "release":
# "SDRzSUFBQUFDLyt6OWE1T2l5cl2RGmpuNzVuTm05QU12cWRrYnNpQzFXaVZCS1RWRzVQV3ZIQ1RLeEF
# VMlFWVjd4eFA3dS84amtqcWlBVnMvdXRlcEZSM1NwSkhrWk9lN2pOLzdmWjg5dzU1Ly8vTHpjZ3ZrWC8
# yM2x6amYyZkx2K3N0NFljUG41ajgrTzkyUDErYy8vOS9t...
# base64 decode > kubernetes secrets 디코딩
# base64 decode > Helm 디코딩
# gzip > Helm decompress
kubectl get secrets sh.helm.release.v1.kube-prometheus-stack.v1 -o jsonpath='{.data.release}' | base64 -d | base64 -d | gzip -d
형식이 깨지긴 하지만 보이긴 함

- helm import 같은 명령어는 없는건지
- 리소스의 annotation에 helm 관련 tag 다 남아있는데 helm list로 조회될수 있도록 재설정이 가능할지에 대한 의문
- 일단은.. 클러스터 부수고 다시만들어서 과제수행..